
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- graphrag
- 인턴10
- Rag
- parklab
- ux·ui디자인
- DP
- 알고리즘
- likelionlikelion
- SQL
- GIS
- BFS
- 멋쟁이사자처럼
- folium
- likelion
- DFS
- 멋사
- TiL
- intern10
- 시각화
- 파이썬
- paper review
- 그리디
- seaborn
- 마이온컴퍼니
- Join
- 프로젝트
- 마이온
- Python
- GNN
- 멋재이사자처럼
- Today
- Total
목록전체 글 (111)
지금은마라톤중
 Midproject_(1)_서울시 1인가구 거주지 추천 서비스
Midproject_(1)_서울시 1인가구 거주지 추천 서비스
2023.03.02 첫 미드 프로젝트를 하였다. 주제가 중간에 엎어지면서 주제를 다시정해서 밤새가며 진행했다. 서울시에 거주하는 20~30대 1인 가구원들에게 지역을 제안해주는 서비스를 만들려고 했다. 이번 포스팅에서는 내가 진행한 전처리에 대해서만 작성하려고 한다. 인구 수는 줄어 들고 있지만, 가구수는 늘어나는 서울의 인구. 1인 가구의 연령분포는 주로 사회초년생 등 청년층이 구성하고 있으며 경제적인 자유도가 핵심 생산 연령층에 비해 떨어지기 때문에 서울에서 생활하기 위해 고려할 사항이 더 많다. 서울에서 살아가기 위해 이들이 중요하게 보는 지표 등은 무엇이 있는지 세부적으로 분석하여 우선순위별 입지를 알아보고자 한다. 거주지 선택 시 주요사항 - 치안 - 녹지 - 전월세 - 대중교통 - 편의시설 팀..
 Miniproject_(3)_boxoffice
Miniproject_(3)_boxoffice
2023.02.04 이번 미니프로젝트는 KOFIC 영화진흥위원회 홈페이지의 데이터를 사용하여 진행하였다. KOFIC에서 제공하는 박스오피스 데이터와 영화제 수상정보 데이터를 활용하여 영화제 수상이 해당 제작사와 배급사 주가에 영향을 미치는지는 분석해보려고 했다. https://www.kofic.or.kr/kofic/business/main/main.do 영화진흥위원회 홈페이지입니다.(1) 웹매거진 한국영화 영화산업계 주요 이슈를 취재, 분석하여 영화업, 영화정책 연구 분야 종사자에게 제공하는 월간지입니다. 한국영화연감 영화진흥위원회가 매년 발간하는, 한국영화 산업 현 www.kofic.or.kr import pandas as pd import numpy as np from glob import glob ..
 Miniproject_(2)_국민청원_scrapping
Miniproject_(2)_국민청원_scrapping
스타벅스 api와 같이 국민청원 페이지의 정보를 스크랩핑해오는 미니프로젝트를 진행하였다. import pandas as pd import numpy as np import requests from bs4 import BeautifulSoup as bs import json from pandas.io.json import json_normalize import datetime 스타벅스 api는 post 방식이었지만 국민청원은 get방식을 사용하여 쿼리스트링을 url 뒤에 붙여 불러왔다. page_no = 1 url = f'https://petitions.assembly.go.kr/api/petits?pageIndex={page_no}&recordCountPerPage=8&sort=AGRE_END_DE-&s..
 Miniproject_(1)_starbucks_API
Miniproject_(1)_starbucks_API
첫 미니 프로젝트이다. 스타벅스 api를 활용하여 지도에 지역과 매장타입을 입력 받으면 매장의 위치를 마크업하는 함수를 구현하였다. 또한 매장간 거리 차이를 이용하여 상도덕이 없는 매장은 어디인가? 라는 주제로 분석을 해볼려고 했다. 수업에서 계속 csv 파일만 이용하다가 json 형식을 처음 사용해보았다. 불러오는 방식부터 데이터프레임으로 만드는 방법까지 차이가 있어 처음에 당황했다. 불러올 때는 json.load(변수), 데이터프레임으로 만들 때는 json_normalize()를 사용한다. import pandas as pd import requests import json from pandas.io.json import json_normalize # jsnon을 데이터프레임으로 만들 때 사용 fro..
 Seaborn Tutorial (5)_Similar functions for similar tasks
Seaborn Tutorial (5)_Similar functions for similar tasks
2023.03.01 시본의 네임스페이스는 평평하다; 기능의 모든 것들이 최상위 수준으로 접근이 가능하다는 것이다. 그러나 코드 자체는 다른 방법을 통해 비슷한 시각화 기능을 가진 모듈과 계층적으로 구조화되어있다. 대부분의 문서들을 이런 모듈들로 구성되어있다: "관계형", "분포형", "분류"와 같은 이름을 접하게 될 것이다. 예를 들어, 분포 모듈은 데이터 포인트의 분포를 나타내는 것을 전문으로 하는 기능을 정읳ㄴ다. 여기에는 히스토그램과 같은 친숙한 방법이 있다. penguins = sns.load_dataset("penguins") sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack") 커널 밀도 추정과 같..
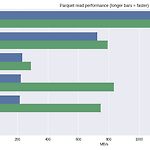 멋사 AI스쿨 TIL - (16)
멋사 AI스쿨 TIL - (16)
2023.02.09 오늘 포스팅은 수업이 아니고 과제이다. 주제는 "메모리 부담 줄이는 법" 이다. 사실 오늘은 2023.02.28일이다. 그간 조금 밀렸던 포스팅을 지금에서야 올린다.. + 미드프로젝트가 생각보다 너무 집중이 필요했다 + 과제였지만 빠르게 수업시간에 한번 더 설명해주셨다. -> 그래서 지금 올린다~ 1. 용량 줄이는 방법 : Parquet - 열의 값은 물리적으로 인접한 메모리 위치에 저장 - 열 단위 압축은 저장 공간에서 효율적 - 열 값이 동일한 데이터 타입이기 때문에 압축에 유리 - 각 열의 데이터 유형에 특정한 인코딩 및 압축 기술을 사용 - 특정 열 값을 가져오는 쿼리는 전체 행을 읽을 필요가 없으므로 성능이 향상 # 파일 사이즈 bytes 로 표기하기 def convert_b..
 Seaborn Tutorial (4)_Opinionated defaults and flexible customization
Seaborn Tutorial (4)_Opinionated defaults and flexible customization
Seaborn은 단일 함수 호출로 완전한 그래픽을 만든다. 가능한 경우, 그 함수는 플롯의 의미 매핑을 설명하는 정보 축 라벨과 범례를 자동으로 추가한다. seaborn은 또한 데이터의 특성에 따라 매개 변수의 기본값을 선택한다. 색상맵핑은 색조에 할당된 범주형 변수의 다른 수준을 나타내기 위해 뚜렷한 hue(파란색, 주황색, 때로는 녹색)를 사용한다. 숫자 변수를 매핑할 때, 일부 함수는 연속 그라디언트로 전환된다. sns.relplot( data=penguins, x="bill_length_mm", y="bill_depth_mm", hue="body_mass_g" ) 모든 그림에 적용되는 여러 내장 테마를 정의하고, 그 기능에는 각 플롯에 대한 시맨틱 매핑을 수정할 수 있는 표준화된 매개 변수가 있으..
 Seaborn Tutorial (3)_Multivariate views on complex datasets
Seaborn Tutorial (3)_Multivariate views on complex datasets
seaborn 함수는 여러 종류의 플롯을 결합하여 데이터 세트에 대한 유익한 요약을 빠르게 제공한다. 그 중 하나인 jointplot()은 단일 관계에 초점을 맞춘다. 그것은 각 변수의 한계 분포와 함께 두 변수 간의 공동분포를 시각화한다. penguins = sns.load_dataset("penguins") sns.jointplot(data = penguins, x= "flipper_length_mm", y = "bill_length_mm", hue = "species") pairplot() 은 더 넓게 표현한다. : 각각 모든 쌍별 관계와 각 변수에 대한 공동 및 한계 분포를 보여준다. sns.pairplot(data=penguins, hue="species") 도표를 만들기 위한 낮은 수준의 도구..