
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 그리디
- 알고리즘
- intern10
- kgc
- 멋사
- TiL
- tog
- parklab
- 파이썬
- 멋쟁이사자처럼
- 인턴10
- likelion
- Join
- likelionlikelion
- seaborn
- GNN
- paper review
- ux·ui디자인
- graphrag
- DFS
- 마이온
- 프로젝트
- DP
- SQL
- 시각화
- folium
- 멋재이사자처럼
- Rag
- 마이온컴퍼니
- Python
- Today
- Total
지금은마라톤중
멋사 AI스쿨 TIL - (16) 본문
2023.02.09
오늘 포스팅은 수업이 아니고 과제이다.
주제는 "메모리 부담 줄이는 법" 이다.
사실 오늘은 2023.02.28일이다. 그간 조금 밀렸던 포스팅을 지금에서야 올린다..
+ 미드프로젝트가 생각보다 너무 집중이 필요했다
+ 과제였지만 빠르게 수업시간에 한번 더 설명해주셨다.
-> 그래서 지금 올린다~
1. 용량 줄이는 방법 : Parquet
- 열의 값은 물리적으로 인접한 메모리 위치에 저장
- 열 단위 압축은 저장 공간에서 효율적
- 열 값이 동일한 데이터 타입이기 때문에 압축에 유리
- 각 열의 데이터 유형에 특정한 인코딩 및 압축 기술을 사용
- 특정 열 값을 가져오는 쿼리는 전체 행을 읽을 필요가 없으므로 성능이 향상

# 파일 사이즈 bytes 로 표기하기
def convert_bytes(num):
"""
1024 보다 크면 숫자를 나누고 아니면 숫자와 단위를 표시하도록
for문을 돌면서 값을 1024로 나누고
값이 1024 보다 작다면 단위와 함께 num 을 반횐
"""
for fs in ['bytes', 'KB', 'MB', 'GB', 'TB']:
if num < 1024 :
return(f"{num:.0f} {fs}")
num /=1024
def file_size(file_path):
"""
파일이 있다면 convert_bytes 함수를 통해 크기를 구함
"""
if os.path.isfile(file_path):
file_info = os.stat(file_path)
return convert_bytes(file_info.st_size)def compare_csv_parquet(a):
"""
데이터프레임을 csv 와 parquet형식으로 저장하하고 각 파일 사이즈를 dict 형태로 반환
"""
file_path_parquet = "data/df.parquet.gzip"
file_path_csv = 'data/df.csv'
df.to_parquet(file_path_parquet, compression = "gzip")
df.to_csv(file_path_csv, index=False)
return {"parquet" : file_size(file_path_parquet), "csv" : file_size(file_path_csv)}
compare_csv_parquet(df)
# {'parquet': '3 MB', 'csv': '25 MB'}저장 후에 다시 읽어와 info() 실행시간 비교
%time pd.read_parquet(file_path_parquet).info()
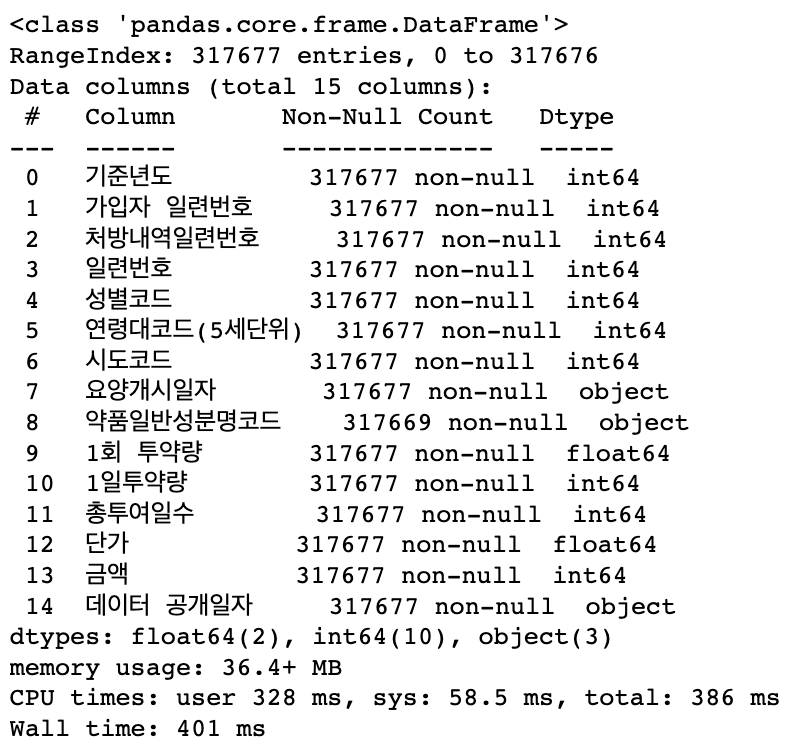
%time pd.read_csv(file_path_csv).info()
# parquet으로 용량을 줄이기 실행 시간이 줄어든 것을 확인할 수 있었다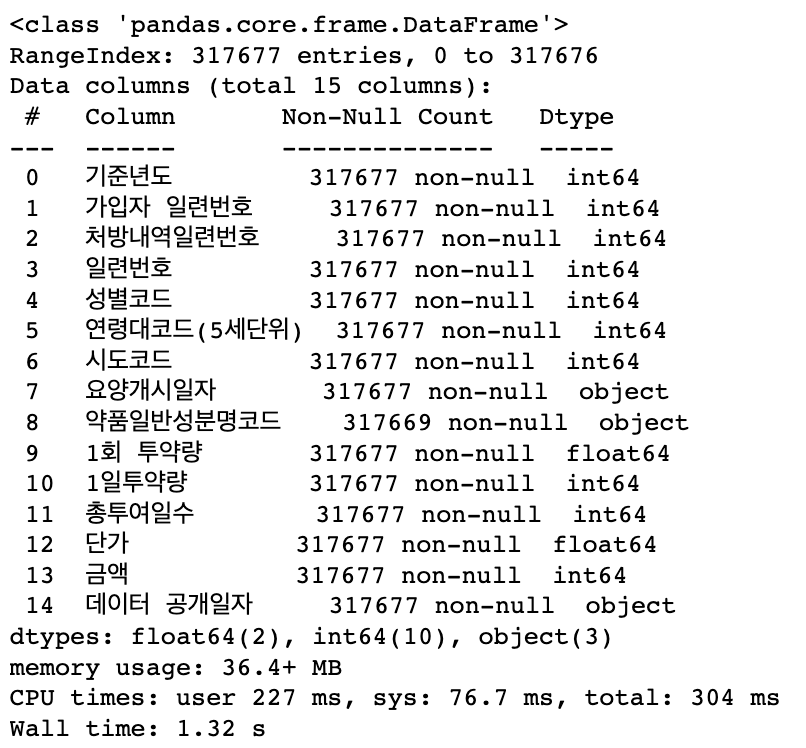 |
 |
| 질문🙋🏻♂️ : 파일 사이즈를 줄여야하는 이유? - “데이터를 저장하는 것” 자체가 “비용”이기 때문에 - 데이터가 누적이 될수록 파일 사이즈는 증가하기 때문에 - 주고 받기 편하게 하기 위해서 - 시간, 메모리 사용량 , 비용 등등 자원 절약을 위해 ex) 노트북을 구매하기 위해 용량을 1T, 2T 등을 고민할 수 있는데 용량에 따라 비용이 20~30만원까지 차이가 납니다. 기업에서는 Log를 쌓을 때 데이터 엔지니어는 시간 단위로 파일을 저장할 것인지 , 어떤 기준, 어떤 도구로 데이터를 저장할 것인지를 고민하게 됩니다. |
| 질문🙋🏻♂️ : Parquet 의 장점? - parquet는 열 단위로 데이터를 관리하는 컬럼형 파일 포맷 - 열 단위로 데이터를 저장하기 때문에 같은 타입의 데이터가 연속적으로 저장됩니다. - 압축 효율성이 높아져 디스크 공간을 절약할 수 있습니다. - 특정 열에 대한 조회(쿼리)를 할 때 필요한 데이터만 읽어오기 때문에 읽기 성능이 빨라집니다. - 특정 열에 대한 집계 등의 처리를 할 때 유리합니다. - parquet는 다양한 데이터 타입을 지원합니다. - 다양한 종류의 데이터를 하나의 파일에 저장할 수 있습니다. |
|
팁 ❗️
기업에서는 parquet라는 형태로 데이터를 저장 Apache Parquet는 Apache Hadoop 에코시스템의 무료 오픈 소스 열 지향 데이터 스토리지 형식
열 단위 압축은 **효율적이고 저장 공간을 절약** 각 열의 데이터 유형에 특정한 인코딩 및 압축 기술을 사용할 수 있습니다. 특정 열 값을 가져오는 쿼리는 전체 행을 읽을 필요가 없으므로 **성능이 향상**됩니다 |
| 질문🙋🏻♂️ : parquet 는 열단위로 저장해서 압축률이 높다고 했는데 왜 parquet 가 용량이 더 클까요?
데이터가 아주 작을 경우에는 메타정보를 포함하고 있지 않기 때문에 메타정보를 포함하고 있지 않은 것이 파일의 크기가 더 작을 수 있습니다
|
|
팁 ❗️
ETL(data ware house) => ELT(data lake)
ETL(Extract, Transform, Load)과 ELT(Extract, Load, Transform)는 데이터 웨어하우스에 데이터를 수집, 가공, 저장하는 방법론 중 하나입니다.
ETL은 데이터를 추출하여(Extract) 전처리 및 가공(Transform)한 후, 데이터 웨어하우스에 적재(Load)하는 방식입니다.
|
| 질문🙋🏻♂️ : 실습에서는 1/10로 압축이 되었지만 반드시 1/10로 압축이 되는 것은 아닙니다. 데이터에 따라 다르게 압축이 되는데 왜 그럴까요? 담고 있는 데이터의 사이즈와 종류에 따라 범위가 달라진다 꼭 1/10이 아니다.
|
2. 메모리 줄이는 법 : downcast
- 파일 불러올 때 메모리를 불러올 때 줄여준다.
- 다운 캐스트로 데이터 타입을 바꿔 메모리를 낮춘다.
- Data typeDescription
| bool | Boolean (True or False) stored as a byte |
| int | Platform integer (normally either int32 or int64) |
| int8 | Byte (-128 to 127) |
| int16 | Integer (-32768 to 32767) |
| int32 | Integer (-2147483648 to 2147483647) |
| int64 | Integer (9223372036854775808 to 9223372036854775807) |
| uint8 | Unsigned integer (0 to 255) |
| uint16 | Unsigned integer (0 to 65535) |
| uint32 | Unsigned integer (0 to 4294967295) |
| uint64 | Unsigned integer (0 to 18446744073709551615) |
| float | Shorthand for float64. |
| float16 | Half precision float: sign bit, 5 bits exponent, 10 bits mantissa |
| float32 | Single precision float: sign bit, 8 bits exponent, 23 bits mantissa |
| float64 | Double precision float: sign bit, 11 bits exponent, 52 bits mantissa |
| complex | Shorthand for complex128. |
| complex64 | Complex number, represented by two 32-bit floats |
| complex128 | Complex number, represented by two 64-bit floats |
# 반복문을 사용해 컬럼 단위로 순회하며 데이터의 용량을 줄입니다.
# df[col].dtype.name 으로 데이터 타입명을 가져옵니다.
# 각 컬럼의 데이터 타입 이름이 int, float 으로 시작하는지를 봅니다.
# bool 일 때는 int8
# int 일 때는 unsigned
# float 일 때는 float 으로 downcast 합니다.
# downcast 는 pd.to_numeric 을 사용합니다.
#
for col in df.columns :
dtype_name = df[col].dtypes.name
if dtype_name.startswith("int"):
df[col] = pd.to_numeric(df[col], downcast = "unsigned")
print(col, dtype_name)
elif dtype_name.startswith("folat") :
df[col] = pd.to_numeric(df[col], downcast = "float")
print(col, dtype_name)# 메모리 크기가 줄어든 것을 확인합니다.
# 메모리 크기가 36.4 -> 17.3으로 줄어들었다.
df.info()
● 다른 메모리 줄이는 법
- 필요없는 컬럼 삭제
# 다음으로 메모리 줄이는 방법 : 필요없는 컬럼 삭제하기
df = df.drop(columns = ["데이터 공개일자"])
- 갯수가 많은 데이터를 카테고리 형태로 바꿈
- 카테고리 형태로 바꿀 때 주의사항 : nunique 값을 확인해봐라, nuique 값을 확인해서 너무 많으면 카테고리로 바꾸는게 적합X
df["요양개시일자"] = df["요양개시일자"].astype("category")
df["약품일반성분명코드"] = df["약품일반성분명코드"].astype("category")
- 데이터 불러올 때 처음부터 데이터 타입 변경하여 적용
# 데이터를 불러올때 처음부터 데이터타입 변경을 적용할 수 있ㄷ다.
pd.read_csv("data/nhis_drug_sample_2020_3.csv", dtype = {"단가": "float32"})
| 질문🙋🏻♂️ : 파이썬으로 기술적인 방법 외에 컴퓨터의 메모리를 절약해서 사용하는 방법?
컴퓨터 재부팅하기
메모리를 많이 사용하는 크롬브라우저의 탭을 닫거나, 사용하지 않는 주피터 노트북 커널 종료, 동영상 관련 프로그램, 게임 등 리소스를 많이 필요로 하는 프로그램 종료하기, 재부팅하기
|
| 질문🙋🏻♂️ : 메모리를 효율적으로 사용할 수 있는 방법 ?
1. 현재 실행 중인 프로그램 중에 필요하지 않은 것들을 종료시켜 메모리를 확보할 수 있습니다.
2. 백그라운드 프로그램들을 제거하거나 비활성화하여 메모리를 확보할 수 있습니다.
3. 브라우저나 다른 애플리케이션에서 생성되는 캐시 및 기록을 정기적으로 삭제하여 메모리를 확보할 수 있습니다.
4. 가상 메모리 설정을 변경하여 더 많은 메모리를 확보할 수 있습니다.
5. 그래픽 설정을 낮추거나 비활성화하여 메모리를 확보할 수 있습니다.
6. 컴퓨터 재부팅하기 는 진리입니다.
→ 메모리를 많이 사용하는 크롬브라우저의 탭을 닫거나, 사용하지 않는 주피터 노트북 커널 종료, 동영상 관련 프로그램, 게임 등 리소스를 많이 필요로 하는 프로그램 종료하기, 재부팅하기 등등
|
| 질문🙋🏻♂️ : 기업에서는 메모리 관리를 어떻게 ?
- 기업에서는 개인 PC 를 사용하기보다 대용량 파일을 공용 장비에 접근해서 사용하기도 합니다.
- 파일들의 사이즈가 너무 크기 때문에 공용 서버에서 관리한다.
|
| 질문🙋🏻♂️ : 데이터베이스 스키마는 무엇일까요?
컴퓨터 과학에서 데이터베이스 스키마(database schema)는 데이터베이스에서 자료의 구조, 자료의 표현 방법, 자료 간의 관계를 형식 언어로 정의한 구조이다.
이름이 있다면 데이터 타입 길이 등을 표현합니다
|
| 팁 ❗️
파일 사이즈와 메모리의 효율적 관리로 비용을 절감할 수 있습니다!(운영 이슈) 이와 마찬가지로 쿼리를 어떻게 짜느냐에 따라 속도가 달라질 수 있으며, 이에 따라 사용자 경험이 달라질 수 있습니다
|
효율적인 파일관리 요약
- 용량 부담 줄이기 : parquet
- 메모리 부담 줄이기 : downcast
출처 :
-Development update: High speed Apache Parquet in Python with Apache Arrow - Wes McKinney.
'멋쟁이사자처럼 > Python' 카테고리의 다른 글
| 멋사 AI스쿨 TIL - (18) (0) | 2023.03.07 |
|---|---|
| 멋사 AI스쿨 TIL - (17) (0) | 2023.03.07 |
| 멋사 AI스쿨 TIL - (15) (0) | 2023.02.09 |
| 멋사 AI스쿨 TIL - (14) (0) | 2023.02.07 |
| 멋사 AI스쿨 TIL - (13) (0) | 2023.02.06 |

