
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Rag
- 파이썬
- paper review
- BFS
- 그리디
- Python
- 알고리즘
- 마이온
- DFS
- 시각화
- intern10
- GIS
- graphrag
- ux·ui디자인
- 멋사
- 멋쟁이사자처럼
- 마이온컴퍼니
- DP
- likelionlikelion
- 프로젝트
- Join
- seaborn
- SQL
- folium
- GNN
- TiL
- parklab
- 인턴10
- 멋재이사자처럼
- likelion
- Today
- Total
지금은마라톤중
멋사 AI스쿨 TIL - (15) 본문
2023.02.08
오늘은 버거지수에 대한 분석을 진행해보았다.
버거지수란 ?
: 한 도시의 발전 수준은 (버거킹의 개수+맥도날드의 개수+KFC의 개수)/롯데리아의 개수를 계산하여 높게 나올수록 더 발전된 도시라고 할 수 있다.
- 버거지수가 클수록 발전된 도시로 판단
- 버거킹 관련 매장들을 살펴보았다.
df.loc[df["상호명_대문자"].str.contains("버거킹|BKR"), "상호명_대문자"].unique()
| 🙋🏻♂️ 질문 : 현업에서 분석할 때 저런 (주) 버거킹티피 같은 예외적인 경우를 제거해주지 못한다면 어떤 문제가 생길 수 있나요? 크게 문제가 될 수 있나요?? 분석결과에 대한 신뢰를 어느정도 할 수 있느냐의 문제입니다. 지금 사용하는 데이터도 실시간 데이터는 아닙니다. 어느정도의 오차는 고려를 하고 보고서나 대시보드 등을 만든다면 주의사항을 함께 기입해 주면 좋습니다. |
- 같은 브랜드도 다양한 이름들이 있어 unique를 통해 그 부분들을 확인하고 조건에 추가해주었다.
df[df["상호명_대문자"].str.contains(
"버거킹|BKR|맥도날드|멕도날드|맥도널드|McDonald|롯데리아|KFC|케이에프씨")
& (df["상권업종대분류명"] != "음식")]
- corsstab를 통해 시도명 각 브랜드의 갯수를 보았다.
df_skorea = pd.crosstab( index = df_b["시도명"], columns = df_b["브랜드"], margins = True, margins_name = "합계")
df_skorea
sns.heatmap(df_skorea.iloc[:,:4], annot =True, cmap = "Blues", fmt = ".0f")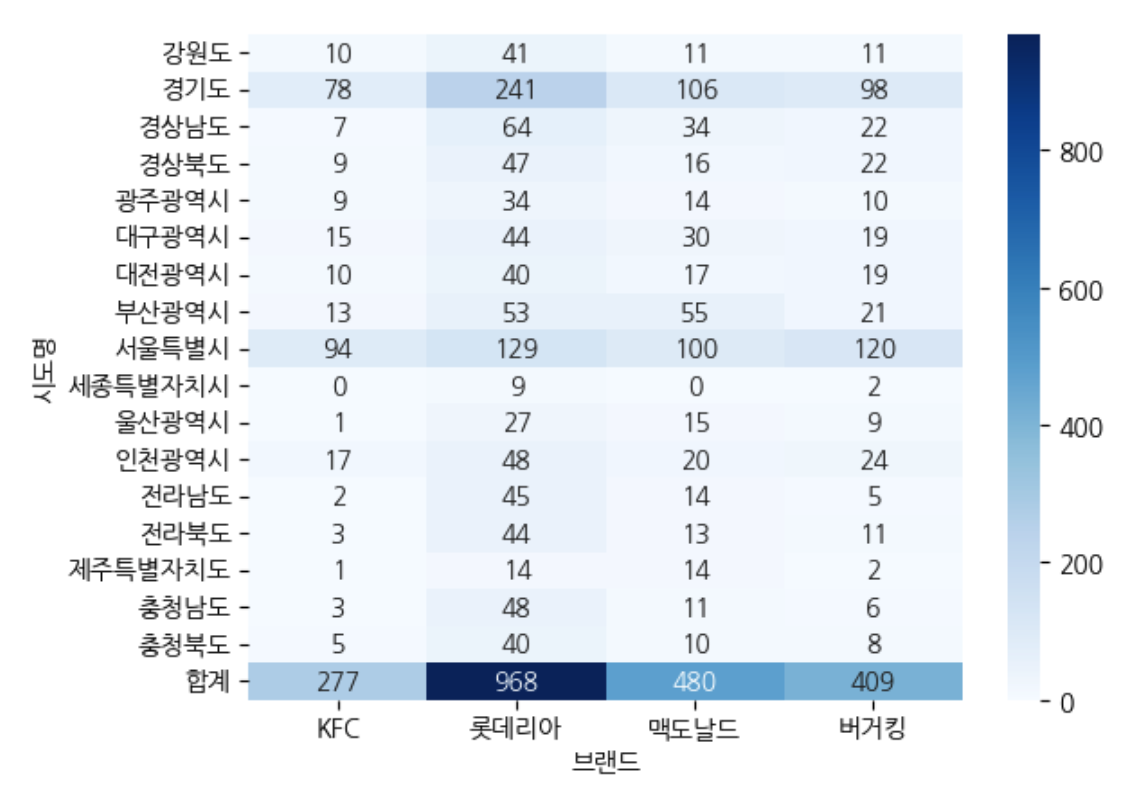
| 🙋🏻♂️ 질문 : 전달하고자 하는 메시지가 무엇인가? heatmap() => 전체 스케일 비교에 적절 style.background_gradient() => 각 변수별 비교에 적절 |
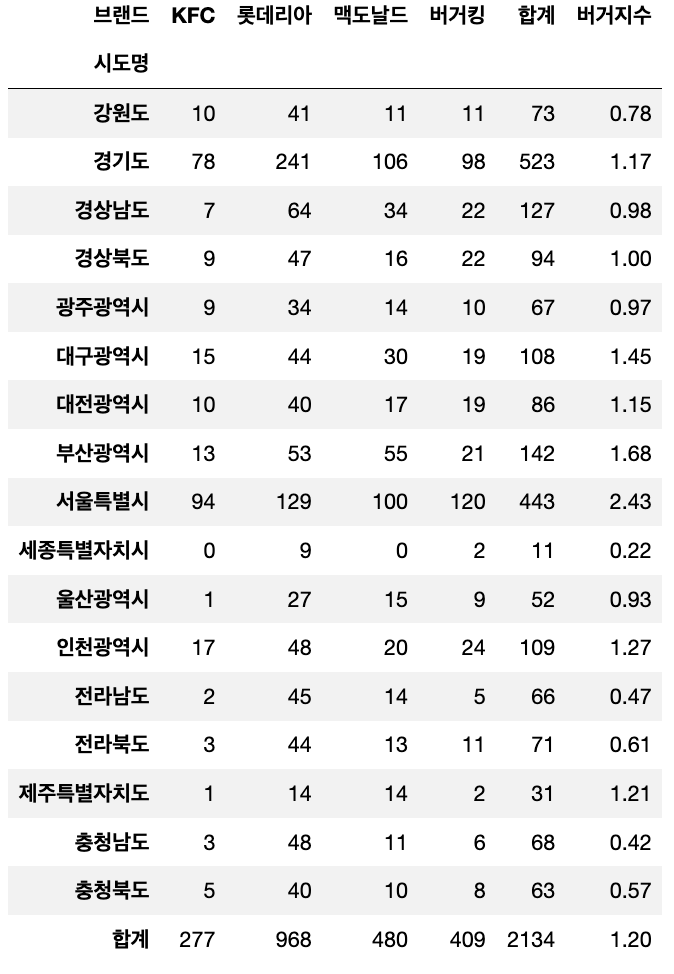
df_skorea["버거지수"] = round((df_skorea["버거킹"] +df_skorea["KFC"] +df_skorea["맥도날드"] ) /df_skorea["롯데리아"], 2)
df_skorea
● 시도별 위도, 경도 평균값 구하기
# 1. 피봇 테이블로 했을 때
# df_city_latlog = df_b.pivot_table(index = "시도명", values=["경도", "위도"])
# 2. 그룹바이로 했을 때
# 2-1. df_b.groupby("시도명")[["위도", "경도"]].mean()
# 2-2. agg를 사용
df_city_latlog = df_b.groupby("시도명").agg({"위도" : "mean", "경도" : "mean"})
df_city_latlog.head()
● inf가 나오는 이유
동해시 같은 경우는 롯데리아가 없어서 버거지수에 숫자가 아닌 inf로 반환되었다.
# df_dist_count["버거지수"]
df_dist_count["버거지수"] = round((df_dist_count["버거킹"] +df_dist_count["KFC"] +df_dist_count["맥도날드"] ) /df_dist_count["롯데리아"],2)
df_dist_count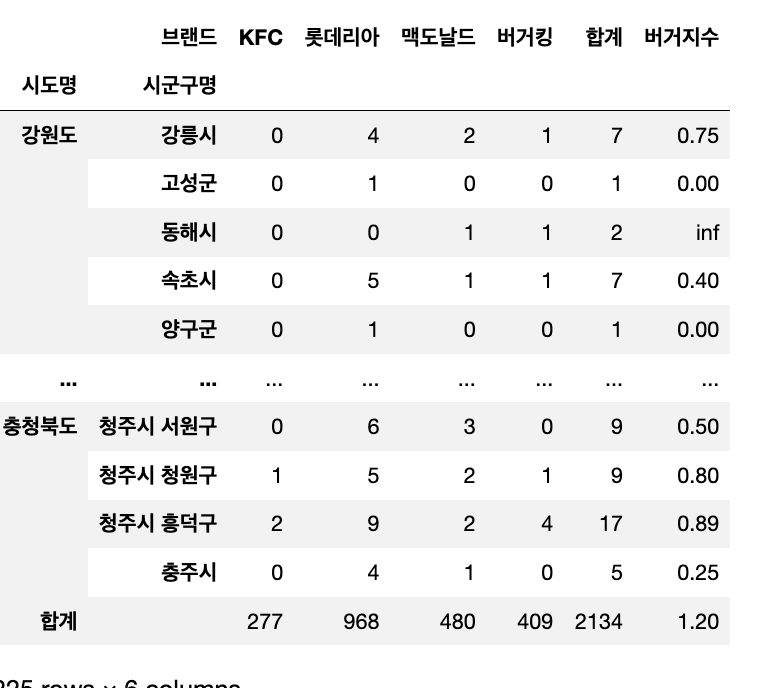
| 🙋🏻♂️ 질문 : 롯데리아가 0개일 때는 inf로 나오는데, 실제로 분석 때 이런 계산 불가한 수치가 나오면 삭제처리를 하게 되나요? 아니면 따로 수치를 입력해주게 되나요? 목적에 따라 다른데, 0으로 처리해도 되는 데이터라면 0으로채우고 0으로 채우면 안 되는 데이터도 있습니다. 그리고 inf 대신 np.nan 등으로 변경해 줄 수도 있겠죠. 결측치라는 의미로 변경해 줄 수도 있을거에요. |
| 🙋🏻♂️ 질문 : 보통 빈도수는 0으로 채우면 되는데 0으로 채우면 안 되는 데이터?무엇이 있을까요? 예를 들어 타이타닉 데이터에서 생존여부를 예측하는데 나이가 중요한 요소인데 나이에 결측치가 많은데 결측치가 있으면 머신러닝 모델이 계산을 할 수가 없어요. 나이를 0으로 채우면 제대로 예측할 수 없습니다. |
| 🙋🏻♂️ 질문 : 그럼 이럴 때 나이를 사용하지 못하게 되는걸까요? 나이를 사용할 수 있는 방법 없을까요? 예를 들어 나이에 결측치가 많은데 나이 변수를 사용하고자 한다면, 구간화(Binning)를 하는 방법이 있습니다. 어린이, 성인, 고령자 등으로 범주화 하는 것이 구간화의 일종입니다. bin 용어는 히스토그램 시각화에서도 막대의 수를 구할 때 사용했습니다. 보통 히스토그램을 시각화 할 때 결측치는 제외하고 시각화 하게 됩니다. DB에서 설정할 때 없는 값은 null 로 관리하는데 가끔 -1 등으로 표기하는 실수를 하기도 합니다. -1 값이 결측치 대신 들어있는데 평균을 계산하면 완전 잘못된 계산을 하게 됩니다
|
상관계수
상관 분석(Correlation analysis) 또는 '상관관계' 또는 '상관'은 확률론과 통계학에서 두 변수간에 어떤 선형적 또는 비선형적 관계를 갖고 있는지를 분석하는 방법이다. 두 변수는 서로 독립적인 관계이거나 상관된 관계일 수 있으며 이때 두 변수간의 관계의 강도를 상관관계(Correlation, Correlation coefficient)라 한다. 상관분석에서는 상관관계의 정도를 나타내는 단위로 모상관계수로 ρ를 사용하며 표본 상관 계수로 r 을 사용한다.
상관관계의 정도를 파악하는 상관 계수( Correlation coefficient)는 두 변수간의 연관된 정도를 나타낼 뿐 인과관계를 설명하는 것은 아니다. 두 변수간에 원인과 결과의 인과관계가 있는지에 대한 것은 회귀분석을 통해 인과관계의 방향, 정도와 수학적 모델을 확인해 볼 수 있다.
● 피어슨 상관계수
- r 값은 X 와 Y 가 완전히 동일하면 +1, 전혀 다르면 0, 반대방향으로 완전히 동일 하면 –1 을 가진다.
- 결정계수(coefficient of determination)는 r^2 로 계산하며 이것은 X 로부터 Y 를 예측할 수 있는 정도를 의미한다.
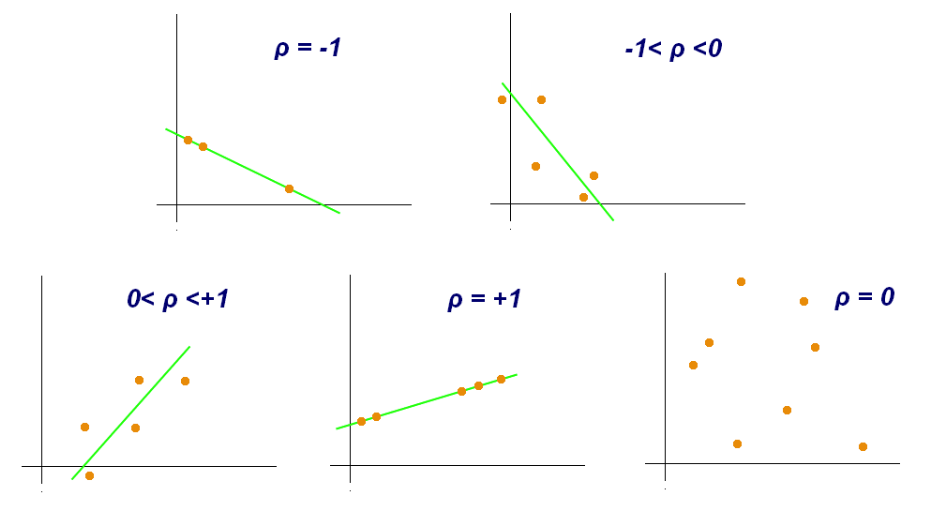
seoul_corr = df_dist_count.loc["서울특별시", burger].corr()
seoul_corr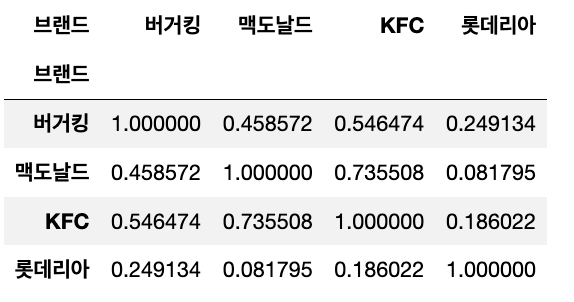
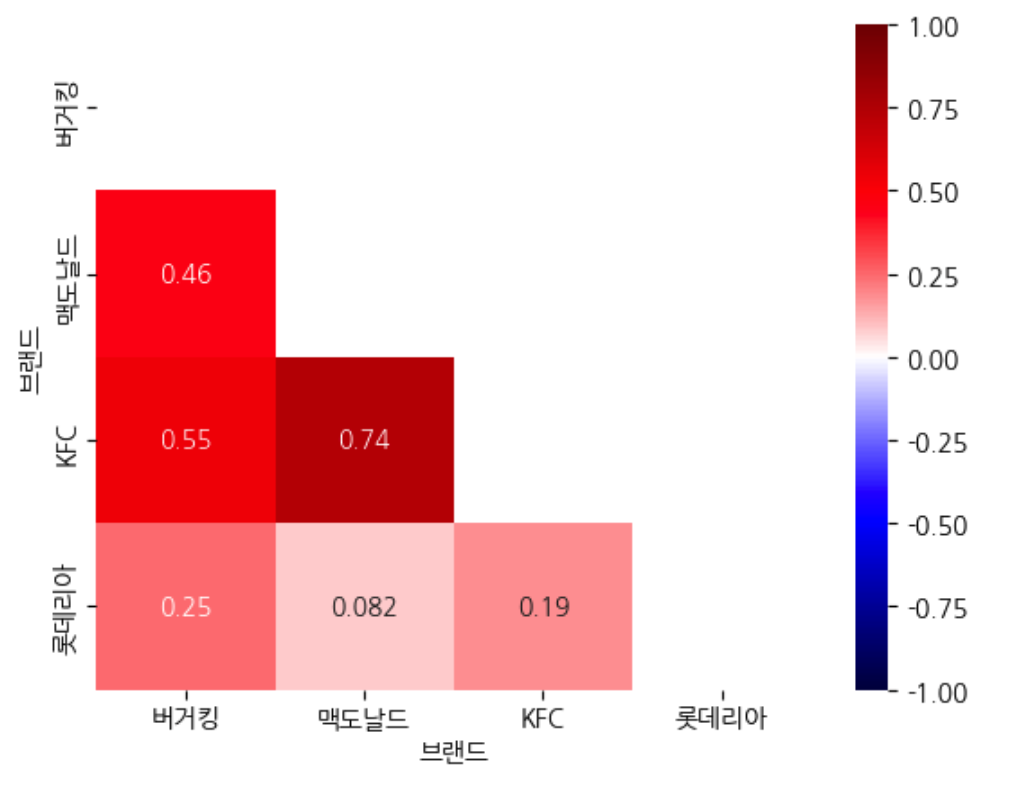
● 삼각행렬을 만들어서 마스크처리하는 방법
- np.triu : 배열의 위쪽 삼각형을 의미
- np.tril : 배열의 아래쪽 삼각형을 의미
# np.ones_like(seoul_corr)
masku = np.triu(np.ones(seoul_corr.shape))
masku
# sns.heatmap()
# mask : 해당 값을 보여주지 않는다.
sns.heatmap(seoul_corr,
annot=True, cmap="seismic",
vmin=-1, vmax=1,
mask=masku
)
● Folium CircleMarker
- CircleMarker로 지도에 브랜드마다 색깔을 다르게하여 표시
f_map = folium.Map(latlong, zoom_start=12, tiles="Stamen Toner")
for i in df_seoul.index:
sub_lat = df_seoul.loc[i, "위도"]
sub_long = df_seoul.loc[i, "경도"]
brand = df_seoul.loc[i, '브랜드']
title = f"{df_seoul.loc[i, '상호명']} - {df_seoul.loc[i, '도로명주소']}"
color = {"롯데리아" : "yellow", "버거킹": "blue", "맥도날드": "orange", "KFC":"red"}
folium.CircleMarker([sub_lat, sub_long],
radius=3,
color=color[brand],
tooltip=title).add_to(f_map)
f_map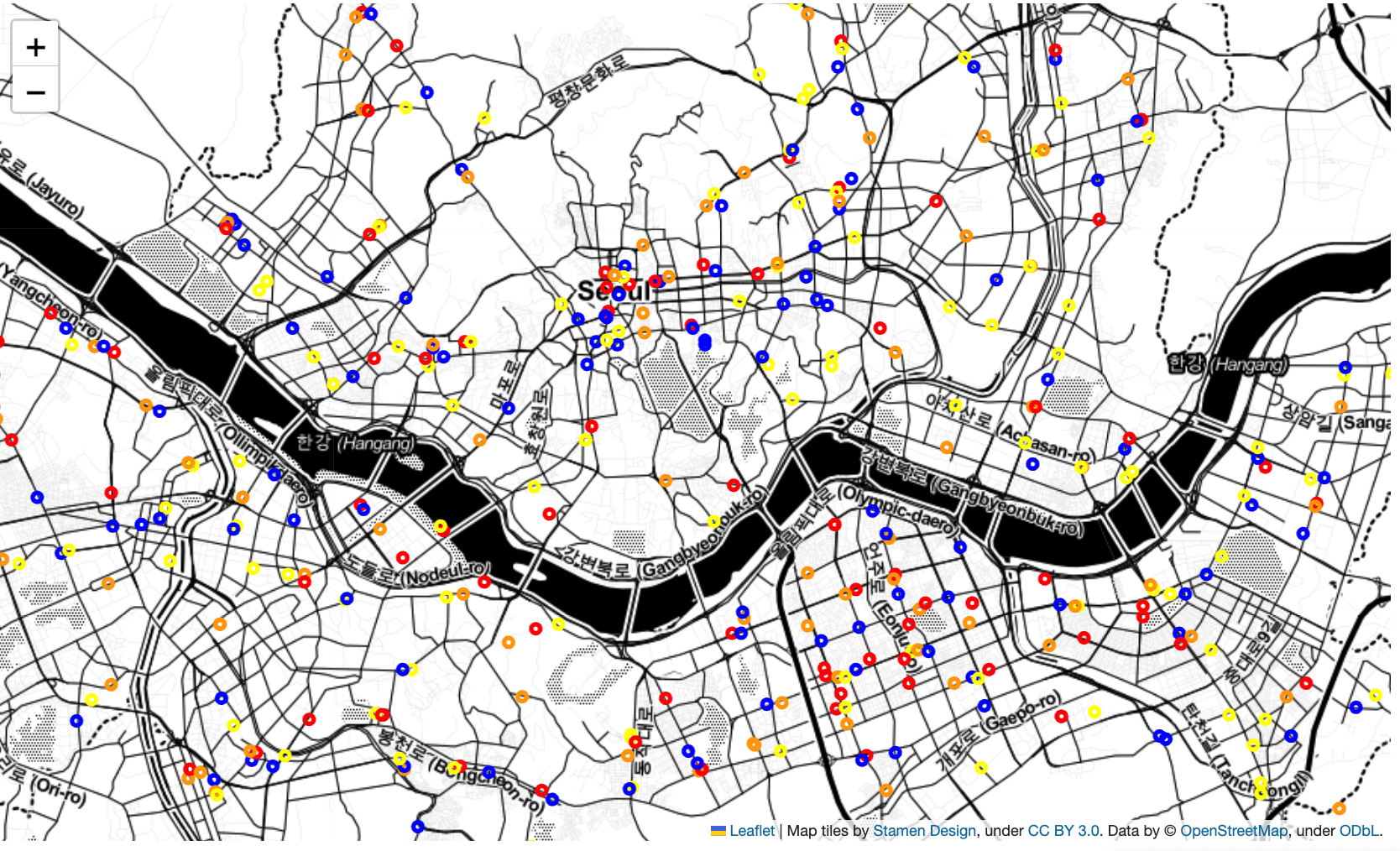
choropleth
- 등치맵 또는 단계 구분도라고 하면 데이터의 범주를 단계별로 나눠 색깔로 구분하여 지도에 시각화한 것을 말한다.
- folium과 plotly 둘 다에서 사용 가능하다.
- geojson 파일을 로드해야한다.
● GeoJSON 파일로드
from urllib.request import urlopen
import json
south_korea_url = "https://raw.githubusercontent.com/southkorea/southkorea-maps/master/kostat/2018/json/skorea-provinces-2018-geo.json"
seoul_geo_url = "https://raw.githubusercontent.com/southkorea/seoul-maps/master/kostat/2013/json/seoul_municipalities_geo_simple.json"
print(south_korea_url)
print(seoul_geo_url)
# 전국 시도 GeoJSON
with urlopen(south_korea_url) as response:
ko_geojson = json.load(response)
ko_geojson["features"][0]["properties"]
# 서울 시도 GeoJSON
with urlopen(seoul_geo_url) as response:
seoul_geojson = json.load(response)
seoul_geojson["features"][0]["properties"]
● plotly choropleth
- 테마설정 : print(dir(px.colors.colorbrewer))
# 시도별 버거지수
fig1 = px.choropleth(df_skorea_index, geojson=ko_geojson, color="버거지수",
locations="시도명", featureidkey="properties.name", labels="시군구명",
projection="mercator", color_continuous_scale=px.colors.colorbrewer.YlGn)
fig1.update_geos(fitbounds="locations", visible=False)
fig1.update_layout(margin={"r":0,"t":0,"l":0,"b":0})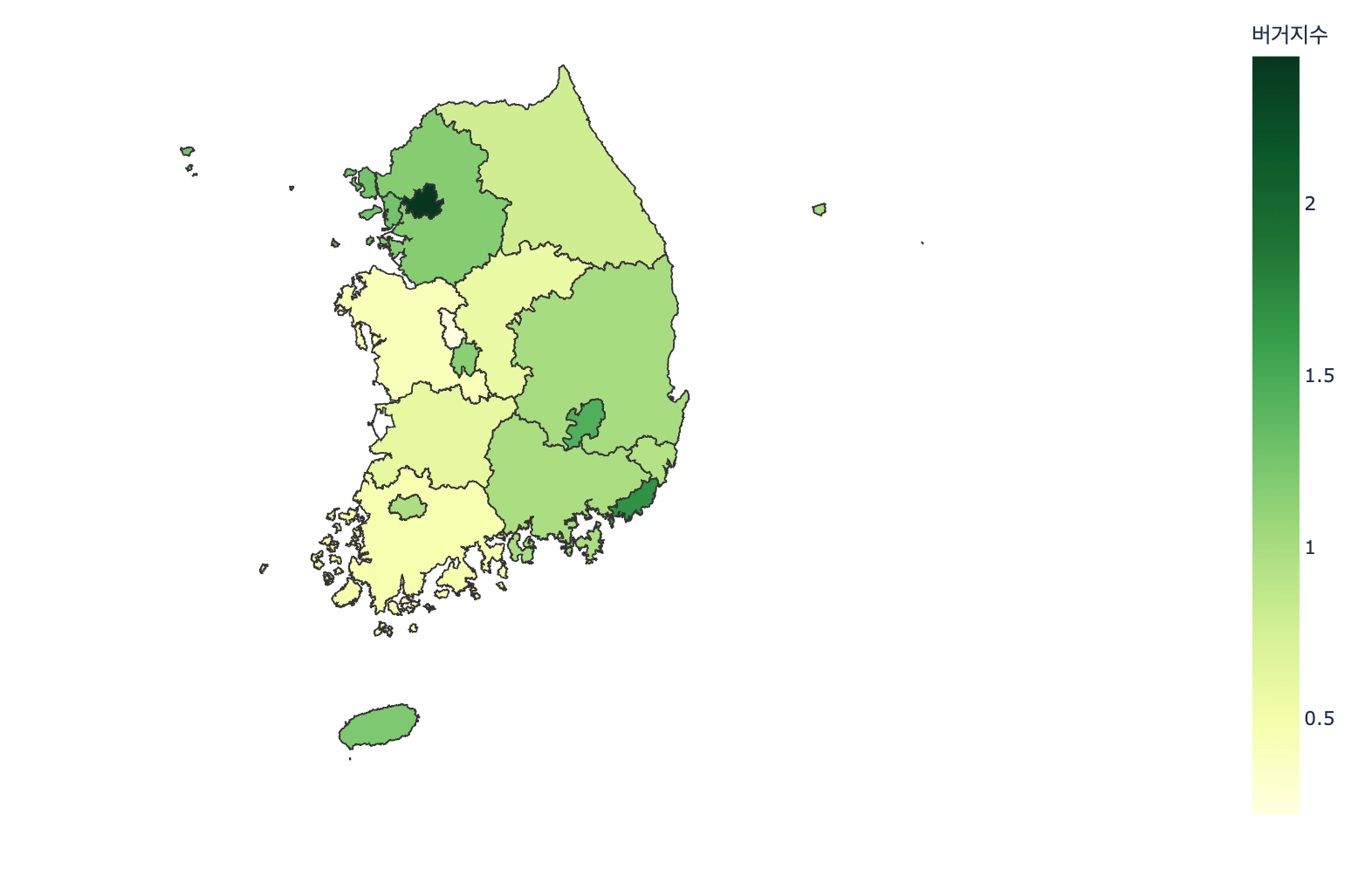
● folium Choropleth
# 전국 Choropleth
f_map1 = folium.Map(latlong, zoom_start=6.5, tiles="Stamen Toner")
folium.Choropleth(
geo_data=ko_geojson,
name='choropleth',
data=df_skorea_index,
columns=['시도명', '버거지수'],
key_on='feature.properties.name',
fill_color='Reds',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='버거지수'
).add_to(f_map1)
f_map1
# folium.Choropleth().add_to(f_map)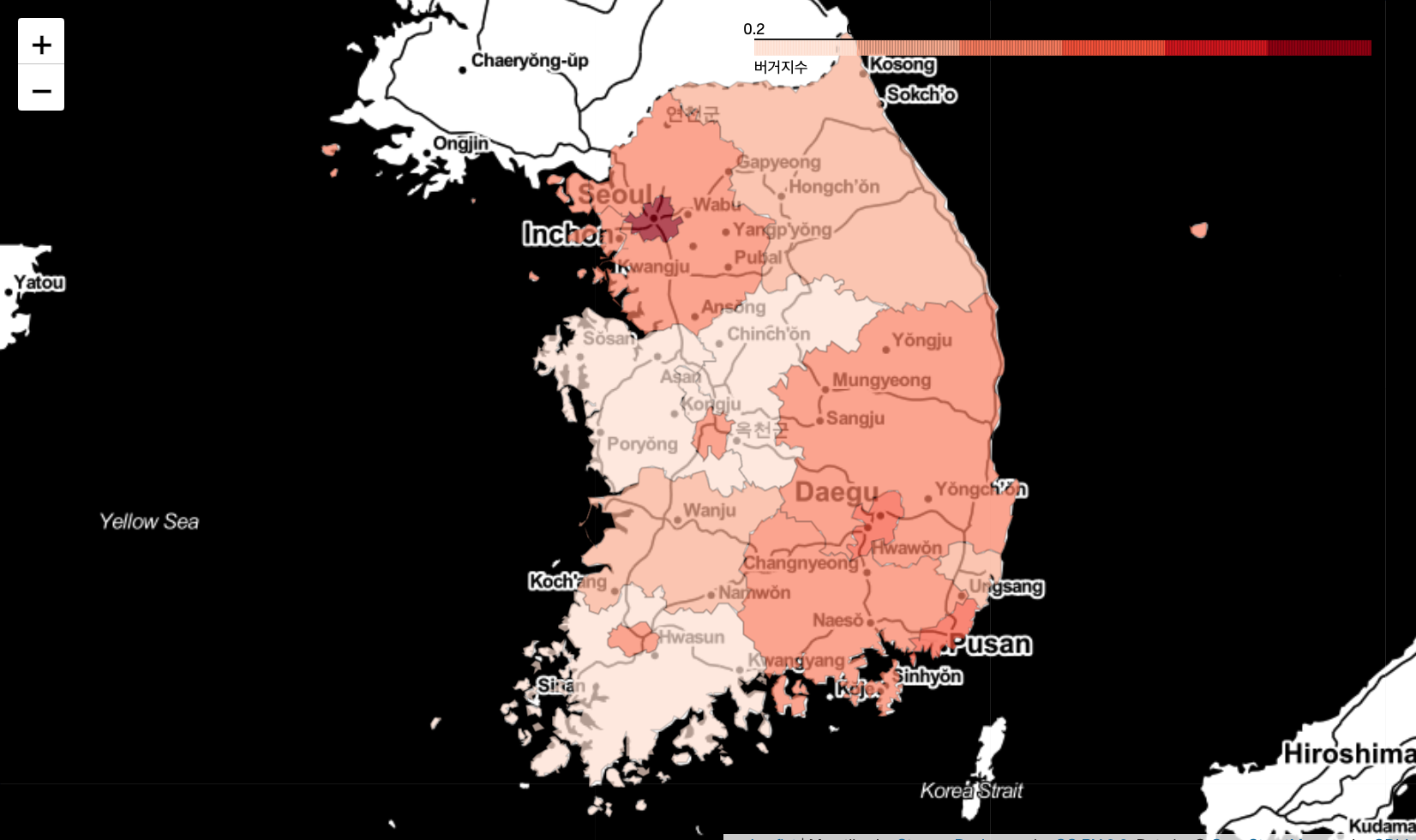
| 🙋🏻♂️ 질문 : Binning은 어느 그래프를 시각화 할 때 이 용어를 사용할까요? 히스토그램 |
● 버거지수 :
* glob 를 사용해서 여러 파일을 로드해서 하나로 합치는 방법
* 상관 계수의 종류, 시각화 하는 방법, 삼각행렬을 만들어서 마스크처리하는 방법, 컬러선택방법
* 지도 시각화 방법
출처 :
- https://ko.wikipedia.org/wiki/%EC%83%81%EA%B4%80_%EB%B6%84%EC%84%9D.
'멋쟁이사자처럼 > Python' 카테고리의 다른 글
| 멋사 AI스쿨 TIL - (17) (0) | 2023.03.07 |
|---|---|
| 멋사 AI스쿨 TIL - (16) (0) | 2023.02.28 |
| 멋사 AI스쿨 TIL - (14) (0) | 2023.02.07 |
| 멋사 AI스쿨 TIL - (13) (0) | 2023.02.06 |
| 멋사 AI스쿨 TIL - (12) (1) | 2023.02.01 |


