
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- seaborn
- Rag
- intern10
- SQL
- likelionlikelion
- 시각화
- 파이썬
- kgc
- 마이온
- folium
- 마이온컴퍼니
- GNN
- Python
- 멋사
- 멋쟁이사자처럼
- ux·ui디자인
- Join
- DP
- 인턴10
- tog
- 그리디
- TiL
- 프로젝트
- parklab
- likelion
- 알고리즘
- 멋재이사자처럼
- paper review
- DFS
- graphrag
- Today
- Total
지금은마라톤중
멋사 AI스쿨 TIL - (12) 본문
2023.02.01

● 왜도
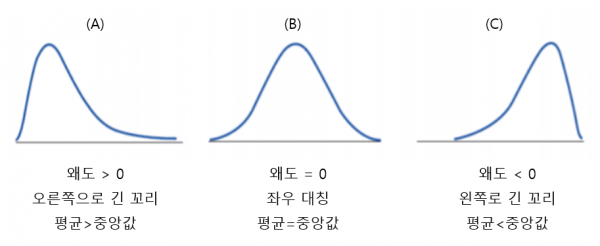
- 왜도는 치우쳐진 정도를 통해 비대칭성을 확인하는 지표이다.
- positive 왼쪽, negative 오른쪽
- 보통은 정규분포 형태가 가장 이상적인 형태입니다.
- 그런데 현실세계에서는 정규분포 형태의 모양을 띄는 경우가 많지 않습니다.
- 머신러닝, 딥러닝 등을 할 때는 정규분포 형태로 분포의 모양을 변경해 주기도 합니다.
● 첨도
- 관측치들이 어느 정도 집중적으로 중심에 몰려 있는가를 측정할 때 사용된다.
- 납작한지 뾰족한지를 확인
- 첨도값(K)이 3에 가까우면 산포도가 정규분포에 가깝다.
- 3보다 작을 경우에는(K<3) 정규분포보다 더 완만하게 납작한 분포로 판단할 수 있으며,
- 첨도값이 3보다 큰 양수이면(K>3) 산포는 정규분포보다 더 뾰족한 분포로 생각할 수 있다.
● concat()을 이용한 병합
- concat(axis=0) => 컬럼명이 같은 여러 데이터를 불러와서 병합할 때 , 예, 기간별로 나뉜 데이터
- concat(axis=1) => 인덱스 값이 같은 여러 데이터를 병합 할 때, 예, 여러 주가를 비교할 때
● high-level interface
- 사람이 이해하기 쉬운 인터페이스,
- 복잡한 기능을 단순하게 만들어 놓은 인터페이스, 추상화
- 기계에 더 가까운 것이 low-level interface , 사람에 더 가까운 것이 high-level interface
● Low Code, No Code
: 인터페이스가 점점 단순해지거나 사용하기 쉽게 만들어지는 추세입니다.
Plotly 는?
: 파이썬의 대표적인 인터랙티브 시각화 도구
| ❗️꿀팁 : 시각화 생각 순서 1) 어떤 그래프로 시각화 할지를 고릅니다 예) 막대, 선, 산점도, 히스토그램 등 2) 어떤 데이터를 시각화 할지 API에 설정해 줍니다. 3) x, y 축을 설정합니다. 4) 제목, 그래프 크기, 범례, 서브플롯, 스타일 등을 설정합니다. 5) bar(data, x, y) 와 유사한 API 를 대부분 갖고 있습니다. |
# px.area 로 수익률 분포를 그립니다.
# facet_col 을 통해 서브플롯을 그릴 수 있습니다.
# facet_col_wrap는 한 행에 넣은 그래프의 갯수를 지정
px.area(df_1, facet_col = "company", facet_col_wrap =2)| 🙋🏻♂️질문 : hover_data={"date": "|%Y-%m-%d"} 로 시간을 표현할 때 연월일 형식 앞에 |를 붙여주는 이유가 궁금합니다. plotly 에서의 약속입니다. API 규칙이에요. |
● Range Slider
- 그래프를 이동하면서 좀 더 세세히 볼 때 range slider 쓸 수 있다
fig = px.line(df_1["GOOG"], title = "구글 주가")
fig.update_xaxes(rangeslider_visible=True)
● scatterplot
- x와 y 간의 상관관계를 볼 수 있다.
- marginal_x = "box" : x축으로 box를 통해 range slider 같은 역할을 할 수 있다.
px.scatter(df_ratio, x = "GOOGL", y = "AAPL", marginal_x = "box")
fig = go.Figure(data=[go.Candlestick(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])])
fig.show()scatter_matrix
- 전체 데이터를 다 scatter로 비교하여 각각의 x와 y 간의 관계를 파악할 수 있다.
px.scatter_matrix(df_ratio)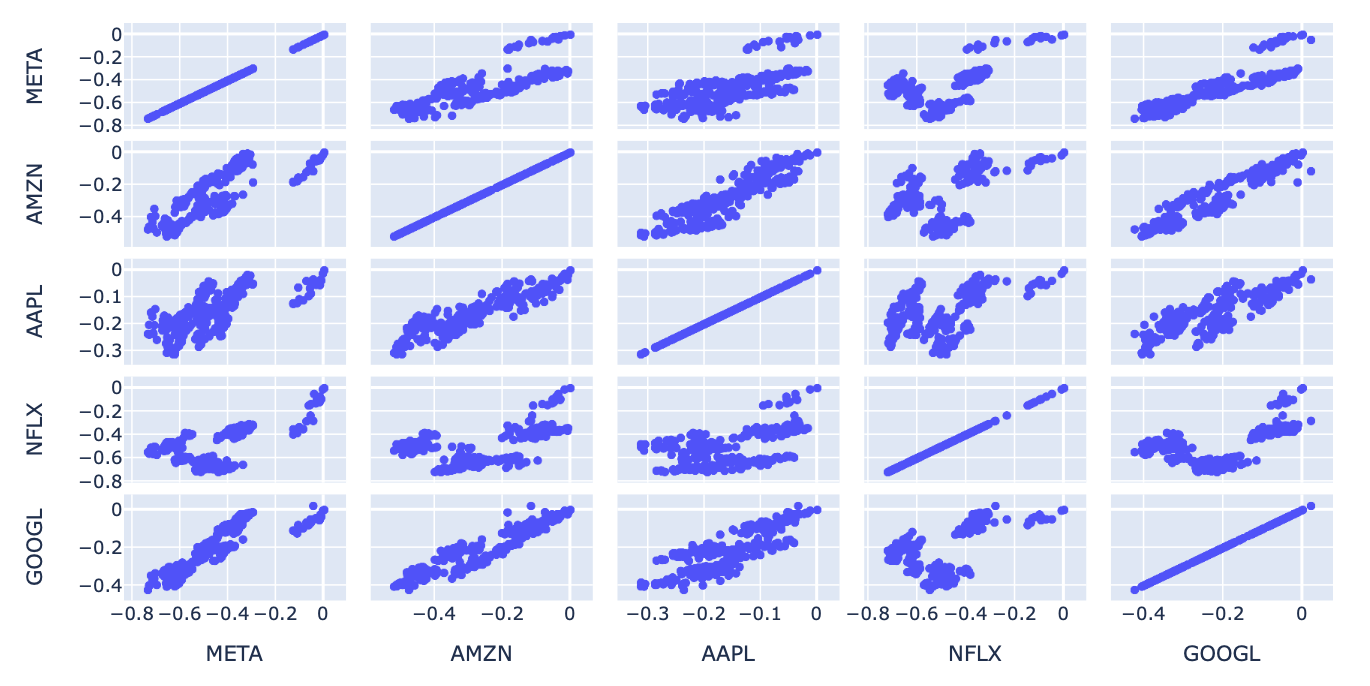
● 캔들스틱 차트

- 봉차트, 일본식 캔들스틱 차트는 주식을 비롯한 유가증권과 파생상품, 환율의 가격 움직임을 보여주는 금융 차트이다.
fig = go.Figure(data=[go.Candlestick(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])])
fig.show()
● OHCL 차트

- 시간와 종가를 방향으로 구분하여 표현하는 차트입니다.
# go.Ohlc를 그립니다.
fig = go.Figure(data=[go.Ohlc(x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close'])])
fig.show()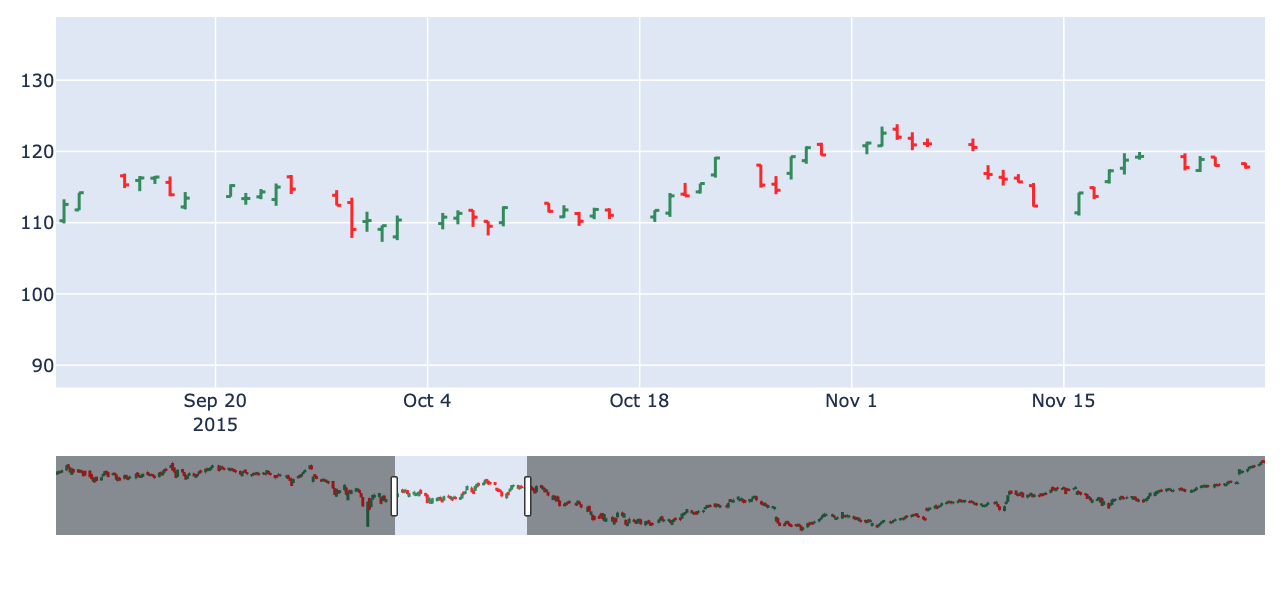
| 🙋🏻♂️질문 : plotly 와 matplotlib 의 차이점? plotly는 자바스크립트 기반이고, 동적으로 그래프를 그릴 수 있습니다. matplotlib은 python(matplotlib) 기반으로, 정적으로 그래프를 그릴 수 있습니다. 판다스는 matplotlib 기반의 high level interface 를 통해 시각화를 제공합니다. |
● matplotlib에서 제공하는 boxplot과 violinplot 비교 설명
 |
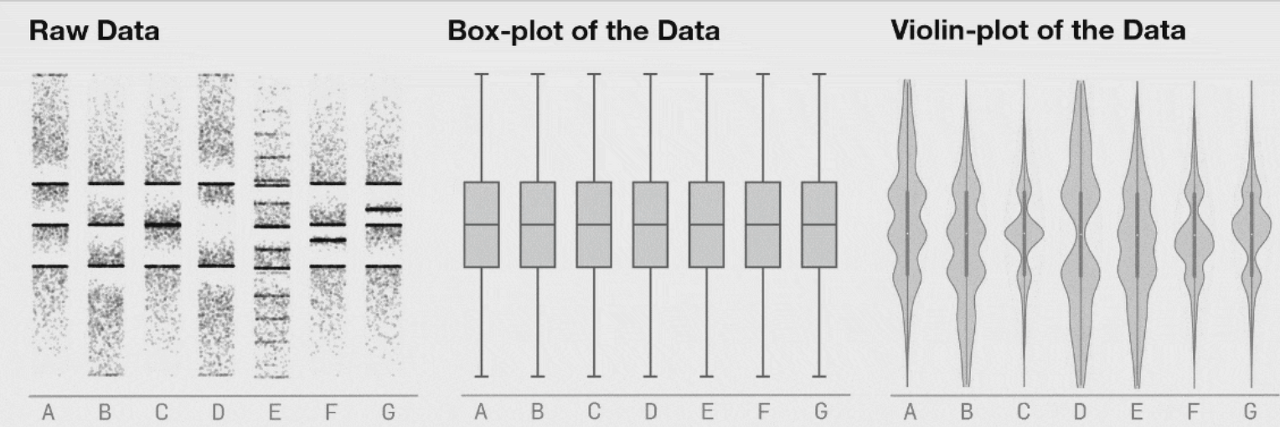 |
- boxplot : 중앙값, IQR 최댓값, 최솟값 이상치
- violinplot : 분포(밀도 추적), 데이터의 전체 범위를 추가로 보여줌
- boxplot은 분포가 바뀌더라도 그래프로 표현이 안 되어 이를 보완하기 위해 나온 것이 violinplot이다.
- boxplot : 사분위수, 중위값(상자 안의 밴드), 이상치(점으로 표현) violinplot : 커널 확률 밀도
| 🙋🏻♂️질문 : EDA를 잘할려면 뭘 공부해야 되나요? 시각화를 잘하면 되나요? 다른 사람이 한 데이터 시각화 사례를 많이 보고 따라해 보고, 직접 여러 데이터를 가져와서 시각화 해보고 의미를 찾아보는 것을 추천합니다 1. raw data 의 description, dictionary 를 통해 데이터의 각 column들과 row의 의미를 이해하는 기술. 2. 결측치 처리 및 데이터필터링 기술. 3. 누구나 이해하기 쉬운 시각화를 하는 기술. |
| 🙋🏻♂️질문 : 엑셀로 실시간으로 업데이트 가능하게 대시보드를 만들 수 있음에도 파이썬을 사용하는 이유? - 엑셀로는 100만 행까지 불러올 수 있습니다. 그런데 파생변수도 만들고 수식도 적용하고 여러 작업을 진행하다보면 현실적으로 가능한 행은 30만행 정도입니다. - 다양한 함수를 제공하고 있지만 파이썬 데이터과학 도구에서 제공하고있는 기능이 훨씬 많습니다. - 30만행 정도로 대시보드를 어느정도 만들어봤다면 속도가 느려져서 대안을 찾게 됩니다. |
| 🙋🏻♂️질문 : high-level interface 용어의 정의 사람이 이해하기 쉬운 인터페이스, 복잡한 기능을 단순하게 만들어 놓은 인터페이스, 추상화 => 단점이 있다면? - 작업과정을 감싸놓았기 때문에 상대적으로 느리고 자유도가 떨어진다. - 커스텀하게 사용하려면 복잡할 수 있다. => 이미 정해져있는 기능을 사용하기 때문에 마음대로 그리기에는 조금 부족할 수 있습니다. - 내부가 어떻게 구현되었는지 알려면 소스코드를 열어 본다든지의 번거로운 작업이 필요하다. - 내부를 제대로 이해하지 못하고 사용할 수도 있다. -> 모든 라이브러리의 장점이자 단점이라고 할 수 있다. |
● 시각화 도구별 차이점
- pandas, plotly 는 서브플롯을 개별 그래프에서 그릴 수 있게 API를 제공합니다.
- seaborn 에서는 별도의 서브플롯 API를 제공하고 있습니다.
* seaborn 에서는 pie chart를 지원하지 않는다
: pie chart가 가독성이 떨어지기 때문이다. 추천하지 않는 차트이다.
| ❗️꿀팁 seaborn에 있는 차트 종류를 하루에 1개씩 리뷰한다며 시각화의 철학을 익힐 수 있어 시각화 능력을 높일 수 있다. |
오늘 마침 2월 1일이다..시작하기에 날짜가 너무 좋다.
하지 않을 핑계 거리가 없다,,, 고로 해야겠다!!

Example gallery — seaborn 0.12.2 documentation
seaborn.pydata.org
'멋쟁이사자처럼 > Python' 카테고리의 다른 글
| 멋사 AI스쿨 TIL - (14) (0) | 2023.02.07 |
|---|---|
| 멋사 AI스쿨 TIL - (13) (0) | 2023.02.06 |
| 멋사 AI스쿨 TIL - (11) (0) | 2023.01.31 |
| 멋사 AI스쿨 TIL - (10) (0) | 2023.01.31 |
| 멋사 AI스쿨 WIL - (9) (0) | 2023.01.19 |



