
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Join
- GIS
- ux·ui디자인
- likelionlikelion
- 알고리즘
- 인턴10
- 멋쟁이사자처럼
- DP
- 시각화
- paper review
- likelion
- 멋사
- parklab
- Rag
- BFS
- folium
- intern10
- 파이썬
- SQL
- GNN
- 마이온
- seaborn
- DFS
- TiL
- 그리디
- Python
- graphrag
- 마이온컴퍼니
- 멋재이사자처럼
- 프로젝트
Archives
- Today
- Total
지금은마라톤중
멋사 AI스쿨 TIL - (11) 본문
2023.01.31
| ❗️꿀팁 아나콘다는 여러 도구를 한번에 설치해 주기도 하지만 가상환경을 제공해 줍니다. 설치했음에도 불구하고 No Module Not Found 오류가 발생할 때는 보통 여러 버전의 파이썬 혹은 아나콘다 등이 설치되어 있는데 현재 사용하고 있는 위치가 아닌 다른 위치에 설치되었을 때 이런 오류가 발생하게 됩니다. 보통 오류 메시지에 보면 어느 경로에 없다는 메시지가 나오게 됩니다. 해당 경로에 가서 보면 여러 라이브러리가 설치되어있는 폴더를 볼 수 있는데, 해당 위치에 사용하고자 하는 라이브러리를 다운로드 받아 옮겨주면 보통 잘 import 가 됩니다. ( base) <= 아나콘다의 기본 가상환경이라서 해당 가상환경에 설치해 주면 보통 문제가 적게 발생하게 됩니다. |
| 🙋🏻♂️질문 : 메서드 체이닝을 하게 되면 도움말이 잘 동작하지 않습니다. 그럴 때는 어떻게 도움말을 봐야 할까요? - 공식 문서에서 직접 검색 - 떼어서 보는 방법을 추천합니다! * 메서드 체이닝 : year_month = df['연도월'].value_counts().sort_index() 이렇게 이어서 붙이는 것 |
| 🙋🏻♂️질문 : 히스토그램을 통해 얻을 수 있는 정보? - 수치형, 범주형 변수에 상관없이 해당 변수의 빈도수를 알 수 있고 데이터의 전체적인 분포를 볼 수 있다. - 수치 데이터일지라도 연속된 데이터가 아니라 끊어진 데이터가 있음을 볼 수 있다. - 수치 데이터임에도 범주형으로 볼 수 있는 데이터도 있음을 볼 수 있다. |
● 여러 조건으로 검색할 때 -> 괄호 써주기 or 변수 할당하기 (연산자 우선순위)
= 할당
== 같음
!= 다름
● str accessor
- .str로 표현
- .str.upper() : 대문자로 표현
- .str.contains() : 특정문자가 포함된 것을 추출
| 🙋🏻♂️질문 : 영문자를 검색하려면 꼭 대문자로 바꿔서 검색해야하는건가요?? 대소문자를 변경해주지 않으면 대소문자가 섞여있을 때 같은 의미라도 값을 찾지 못할 수 있습니다. 소문자로 변경해도 상관 없습니다. |
| 🙋🏻♂️질문 : value_counts() 이거랑 .value_counts 차이를 잘모르겠습니다 value_counts 오류메시지가 나오지 않아서 헷갈릴 수 있는데 오류입니다. |
| 🙋🏻♂️질문 : .isin(), .str.contains() 어떤 차이가 있을까요? - str.contains : 찾으려는 문자열을 포함만 해도 반환 가능 - isin : 찾으려는 문자열과 정확히 일치해야 반환 가능 isin은 데이터프레임에서도 사용 가능하지만 .str은 시리즈에만 사용 가능합니다 |
● .str.contains()
- 특정 문자열을 포함하는 것을 추출하여 출력
- 완벽히 일치하지 않아도 특정 문자열 포함하는 것을 추출
- 여러개를 연결할 때는 | 를 사용
- 여러개 연결할 때 하나라의 따옴표로 묶기
- and 나 or 보다는 | 사용 -> 정규표현식
df.loc[df['거주구'].str.contains('강남구|송파구|서초구'), '접촉력'].value_counts()
● .isin()
- 특정 문자열을 포함하는 것을 추출하여 출력
- 완벽히 일치하는 특정 문자열 포함하는 것을 추출
- 여러개 연결할 때 각각 "" 따옴표로 묶어주고 ,로 구분하여 나열
df.loc[df['거주구'].isin(['강남구', '송파구', '서초구']), '접촉력'].value_counts()
| 🙋🏻♂️질문 : str.contains()는 왜 시리즈에서만 사용가능할까요? 문자열 accessor 이기 때문입니다. - str accessor는 특정 데이터타입에서만 제공한다. - .upper() 는 문자열에서만 사용가능 https://pandas.pydata.org/docs/reference/series.html#accessors |
| ❗️ 꿀팁 막대 그래프 -> 범주형 데이터 선 그래프 -> 연속된 수치 데이터 에서 주로 사용합니다 |
● 지역구별 국내/해외 확진자 추이 그래프 표현
gu_oversea[['국내', '해외']].sort_values("해외", ascending = False).plot.bar(stacked=True, subplots = True, title = "지역구별 국내/해외 확진자 추이")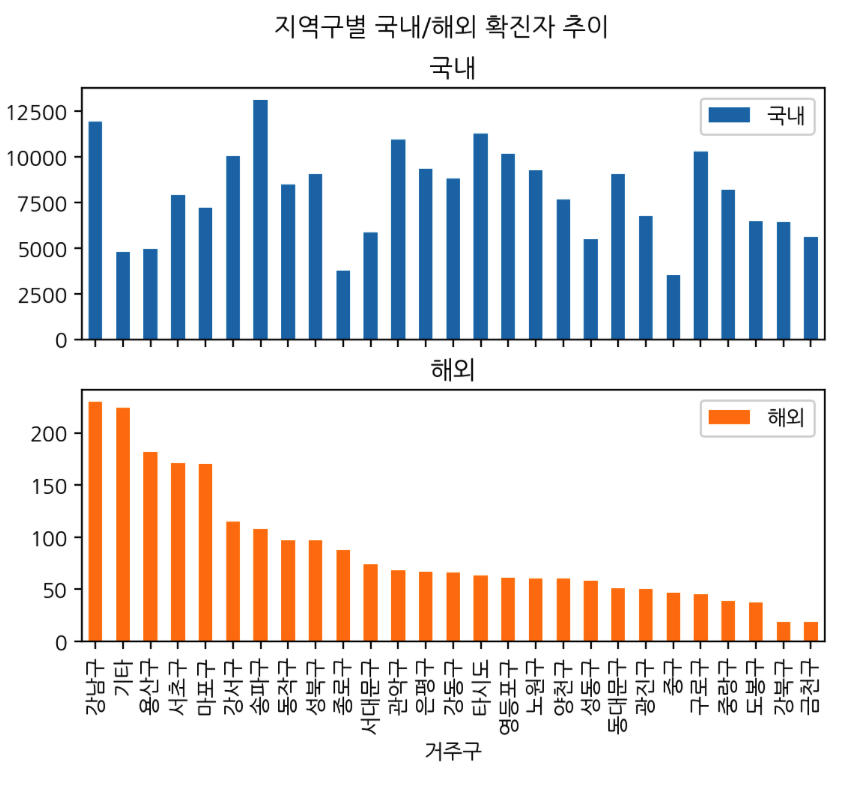
● crosstab()과 pivot_table()
pd.crosstab()의 소스코드를 보게 되면 내부가 pd.pivot_table() 로 되어있습니다.
pd.crosstab() 은 pivot_table()을 사용하기 쉽게 한번 더 감싸(wrapping) 놓은 기능입니다.
pd.crosstab() 에 비해 pivot_table() 을 사용하면 좀 더 많은 기능을 사용할 수 있습니다.
| 🙋🏻♂️질문 : pivot(), pivot_table() 어떤 차이가 있을까요? - pivot, pivot_table 공통점 index, columns, values 를 공통적으로 사용할 수 있습니다. - pivot 은 형태 변환만 제공하고 연산은 제공하지 않습니다. - pivot_table 은 형태 변화과 연산을 함께 제공하고 aggfunc 등의 기능을 제공합니다 - 내부가 groupby()로 되어 있습니다. groupby() 를 사용하기 쉽게 엑셀에서 사용하는 용어로 만들어 놓은 것이 pivot_table() 입니다. - groupby() 는 엑셀 등을 사용했던 사람들은 사용법이 직관적이지 않을 수 있기 때문에 pivot_table() 등의 기능을 제공합니다. |
| 🙋🏻♂️질문 : values에 기준 컬럼을 지정한다고 했을 때 주로 어떤 컬럼을 선택하면 되나요? 일반적으로 결측치와 중복값이 없는 것으로 선택하면 되나요? "환자" 컬럼은 유니크하고 결측치도 없는 것으로 지정해 주시면 됩니다. 중복값이 있더라도 nunique() 가 아니고 count()를 사용하면 빈도를 구합니다. |
'멋쟁이사자처럼 > Python' 카테고리의 다른 글
| 멋사 AI스쿨 TIL - (13) (0) | 2023.02.06 |
|---|---|
| 멋사 AI스쿨 TIL - (12) (1) | 2023.02.01 |
| 멋사 AI스쿨 TIL - (10) (0) | 2023.01.31 |
| 멋사 AI스쿨 WIL - (9) (0) | 2023.01.19 |
| 멋사 AI스쿨 WIL - (8) (0) | 2023.01.12 |
'멋쟁이사자처럼/Python' Related Articles
more




Comments