
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- folium
- 마이온
- 시각화
- 멋쟁이사자처럼
- 프로젝트
- paper review
- likelion
- Rag
- graphrag
- intern10
- Join
- SQL
- 멋재이사자처럼
- BFS
- 파이썬
- 인턴10
- ux·ui디자인
- 마이온컴퍼니
- parklab
- TiL
- seaborn
- likelionlikelion
- 멋사
- Python
- DP
- GNN
- 알고리즘
- 그리디
- tog
- DFS
- Today
- Total
지금은마라톤중
멋사 AI스쿨 WIL - (8) 본문
2023.01.09 ~ 2023.01.11
멋쟁이사자처럼 4주차
2023.01.09
● 데이터베이스
● ETL과 ELT
• ETL => 데이터 웨어하우스
• ELT => 데이터 레이크
* 공공데이터 사이트 추천
- 비정형데이터 => AI Hub
- 정형데이터 => 공공데이터 포털, 통합데이터지도
| 🙋🏻♂️질문: 파이썬은 접착제 언어라는 특징이 있습니다. 접착제 언어가 의미하는건 무엇일까요? • Numpy 대표적인 접착제 언어의 특징을 갖는 라이브러리
• 생태계가 다양한 특징이 있음.
• 내부가 파이썬이 아니고 인터페이스만 파이썬으로 되어 있는 라이브러리, 대표적으로 XGBoost, LightGBM, KoNLPy 등
• 다른 언어로 만들어졌고 파이썬으로 구동하기 위해서는 해당 언어(예, JAVA, C, C++)를 실행할 수 있는 환경이 필요• 아나콘다로 접착제 언어의 특징을 갖는 라이브러리를 설치하게 되면 이런 복잡한 환경에서 구동하는 도구들을 비교적 오류 없이 설치
→ 그래서 나는 아나콘다로 주피터 노트북을 설치했다!! |
● Pandas의 뜻
• Pandas : Panel Data System, Python Data Analysis 를 의미
• Panel 계량경제에서 다차원데이터를 의미
● Null 은 데이터베이스에서 없는 값을 의미합니다.
넘파이에서는 nan 으로 결측치 없는 값으로 표현합니다
| 🙋🏻♂️질문: df["약품명"] == df.약품명 <= 두 번째 방법을 사용하면 동작하지 않을 때가 있습니다. 어떤 경우 일까요?
컬럼명에 특수문자, 띄어쓰기 등이 들어갈 때, 메서드, 프로퍼티, 어트리뷰트 명과 동일할 때
|
내용정리
|
| 크롤링 | 스크랭핑 |
| 웹에서 페이지 및 링크 다운 (웹을 기반으로 작동) |
웹을 포함한 다양한 소스에서 데이터 추출 (반드시 웹과 관련된 것은 아님) |
| 동일한 콘텐츠가 여러 페이지에 업로드 된 것을 인식하지 못하므로 중복제거는 필수적 |
특정 데이터를 추출하는 것이므로 중복 제거가 반드시 필요한 것은 아님 |
5.806200e+04 => * 10^4
● pd.read_html() 의 기능
1) URL, HTML 소스코드를 넣어주게 되면 테이블 태그를 찾아서 반환
2) URL 을 넣어주면 특정 URL 에 접근해서 HTML 페이지의 table 태그를 읽어옴.
3) HTML 페이지의 table 태그는 <table></table> 로 구성.
4) 해당 HTML 의 모든 table을 가져와서 리스트 형태로 반환.
5) 반환된 리스트를 인덱싱하게 되면 데이터프레임으로 되어 있음.
* 서버측에서 요청이 너무 많거나 봇이 너무 많이 접근하면 서버에 부담이 되기 때문에 referer 라든지, bot, IP Address 등을 막음
●셀레니움
: 주로 웹앱을 테스트하는 웹 프레임워크
• 셀레니움 사용하는 이유
- BeautifulSoup의 한계 : "자바스크립트로 동적으로 생성된 정보는 가져올 수 없다!"
- BeautifulSoup를 극복하기 위해
• 셀레니움을 사용해야 할 때는
=> 로그인이 필요할 때, URL 만으로는 수집이 불가할 때 셀레니움을 추천하지 않는 이유
=> 셀레니움은 원래 브라우저를 테스트하기 위한 목적으로 만듬. 무겁고 리소스를 많이 사용합니다.
- requests 를 사용할 수 있다면 requests 를 사용하는 것이 더 효율적
- 사이트가 변경되거나 서버 정책이 변경되면 잘 동작하던 수집코드가 동작하지 않게 되는 경우가 종종 있음
| 🙋🏻♂️질문: 뷰티풀숲은 데이터 수집 도구가 아닙니다. 뷰티풀숲은 어떤 도구일까요? HTML, XML 등에서 원하는 값을 얻기 위해 사용합니다. parsing 도구 입니다. |
● HTML 태그
• HTML 태그에서 id 로 되어있는 것들은 CSS에서 다음과 같이 #으로 표현합니다.
• HTML 태그에서 class 로 되어 있는 것들은 CSS 에서 다음과 같이 .으로 표현합니다.
=> CSS 스타일은 데이터 수집과는 상관 없지만 id, class 값을 통해 해당 태그에 접근할 수 있습니다.
| 🙋🏻♂️질문: 수집할 수 없는 사이트일 때 어떻게 대응해야 하는지? 사이트마다 다 다릅니다. 헤더, 리퍼러, 파라미터 설정, 로그인 등 서버에서 막을 수 있는 한 막아놓은 사이트는 왜 막혔는지 이유를 리버스엔지니어링을 해서 찾아야 합니다. |
내용정리
|
2023.01.11
● url
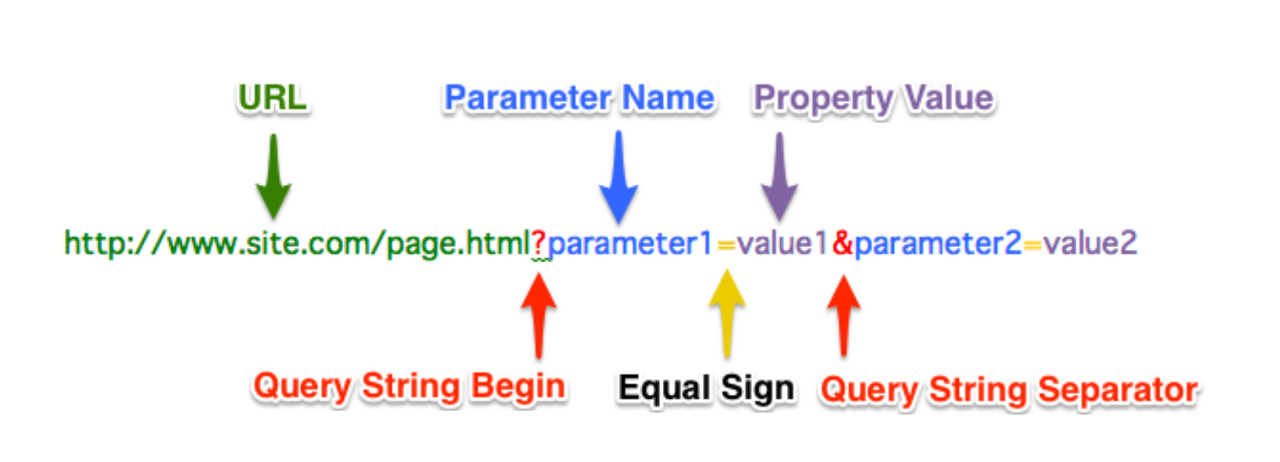
- ? : 쿼리 스트링 시작부분으로 ?에서 끊는게 좋다
- url 구조를 보고 파악할 수 있음
# 종목 URL 만들기
# f-string을 이용하여 url을 수정해주어 변수에 따라 바뀔 수 있게 설정했다.
url = f"https://finance.naver.com/item/sise_day.naver"
url = f"{url}?code={stock_item['삼성전자']}&page={page_no}"
print(url)
● 데이터 프라이버시 관련되서 조금 부연설명
1) 개인정보는 보안규정에 따라 아무나 접근할 수 없음. (DB담당자 소수만 접근 가능).
개인을 식별할 수 없게 키값 등으로 계정을 구분합니다. 연락처, 주소, 이메일, 민감한 정보 등은 절대보안을 지킵니다.
2) 예시 : 특정 데이팅앱 스타트업에서 모 대표가 회원의 정보를 열람해서 처벌을 받음, 회사 대표라고 해서개인정보를 열람 x
3) 특정 개인을 비식별화 하고 개인의 민감한 연락처,주소, 이메일 등의 정보를 제외한 플레이정보, 구매정보, 게임내에서 발생한 모든 정보를 분석
4) 개인정보는 보안규정에 따라 다루게 되고 지키지 않으면 처벌대상
| 🙋🏻♂️질문:. 분석가에게 라이브 권한을 주지 않는 이유는? (DB 권한을 부여할 때 분석가에게는 라이브DB의 열람권한을 주는 곳도 거의 없어요. 복제DB의 읽기권한만을부여하는 편) : 라이브DB에 잘못된 쿼리를 실행하게 되면 서버 장애로 이어질 수도 있습니다. 서비스에 영향이 없는복제DB의 읽기권한만 줍니다. |
| 🙋🏻♂️질문: pd.read_html()로 불러와야할지, requests로 불러와야할지 알 수 있는 방법이 있을까요? - pd.read_html()로 노테이블오류가 나오면 requests로 불러옴. - requests 를 통해 요청을 보내고 오류메시지를 보고 하나씩 리버스 엔지니어링을 하면서 해결 보통 서버설정에 따라다른데 브라우저의 네트워크 정보만으로는 서버 설정을 다 알기어렵 - table 태그가 있는지 확인이 우선, 하나씩 찔러보는 리버스엔지니어링 과정이 필요 찔러보는 방법은 브라우저의 네트워크 정보를 활용하는 것을 추천 |
| 🙋🏻♂️질문: page를 설정하는 파라미터와 한 페이지에 보여지는 분량을 표시하는 파라미터는 무엇일까요? : pageIndex 가 페이지를 나타내고, pageUnit 가 분량을 나타냄. |
내용정리
|
WIL 마무리
이번주는 웹크롤링에 대해 실습을 통해 익힐 수 있었다.
많은 내용들이 있었지만 실습과 함께하니 습득하는데 좋았다.
복습할 시간이 없어서 조금 힘들었지만 다음주부터 틈틈이 정리하면 복습할 때 더 수월할 것 같다.
힘들지만 배우는게 많아 좋다.
출처 :
- https://blog.codef.io/crawling_vs_scraping/.
'멋쟁이사자처럼 > Python' 카테고리의 다른 글
| 멋사 AI스쿨 TIL - (10) (0) | 2023.01.31 |
|---|---|
| 멋사 AI스쿨 WIL - (9) (0) | 2023.01.19 |
| 멋사 AI스쿨 TIL - (7) (0) | 2023.01.06 |
| 멋사 AI스쿨 TIL - (6) (2) | 2023.01.05 |
| 멋사 AI스쿨 TIL - (5) (0) | 2023.01.04 |



