
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- paper review
- TiL
- 파이썬
- tog
- GNN
- 인턴10
- 멋재이사자처럼
- 알고리즘
- 시각화
- Join
- intern10
- Python
- SQL
- BFS
- seaborn
- ux·ui디자인
- Rag
- likelion
- 마이온
- 마이온컴퍼니
- 그리디
- DFS
- DP
- parklab
- 멋쟁이사자처럼
- 멋사
- folium
- 프로젝트
- likelionlikelion
- graphrag
Archives
- Today
- Total
지금은마라톤중
Miniproject_(2)_국민청원_scrapping 본문
스타벅스 api와 같이 국민청원 페이지의 정보를 스크랩핑해오는 미니프로젝트를 진행하였다.
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup as bs
import json
from pandas.io.json import json_normalize
import datetime스타벅스 api는 post 방식이었지만 국민청원은 get방식을 사용하여 쿼리스트링을 url 뒤에 붙여 불러왔다.
page_no = 1
url = f'https://petitions.assembly.go.kr/api/petits?pageIndex={page_no}&recordCountPerPage=8&sort=AGRE_END_DE-&searchCondition=sj&searchKeyword=&petitRealmCode=&sttusCode=PETIT_FORMATN,CMIT_FRWRD,PETIT_END&resultCode=BFE_OTHBC_WTHDRAW,PROGRS_WTHDRAW,PETIT_UNACPT,APPRVL_END_DSUSE,ETC_TRNSF¬InColumn=RESULT_CODE&beginDate=20210121&endDate=20230121&ageCd='
data = {"pageIndex" : "",
"agreBeginDe" : "",
"agreEndDe": "",
"jrsdCmitCode": "",
"jrsdCmitNm": "",
"mberId": "",
"petitCn": "",
"petitEndDt": "",
"petitRealmNm": "",
"petitSj": "",
"resultCode": "",
"resultCodeNm": ""
# "resultCode": "AGRE_END_DSUSE",
# "resultCodeNm": "동의만료폐기"
}
response = requests.get(url, data = data)
# bs(a.text)
jo = json.loads(response.text)
df = json_normalize(jo)
df# 원하는 컬럼을 골라 데이터프레임 만듦.
# 컬렁명을 이해하기 쉽게 바꿈.
df = df[["jrsdCmitCode", "petitRealmNm", "petitSj", "petitCn", "agreBeginDe","agreEndDe", "jrsdCmitNm", "mberId","resultCodeNm"]]
df.columns = ["코드", '분야', '제목', '내용', '동의시작일', '동의마감일', '관리부처', 'id', '청원결과']
df

기간내의 검색결과 중 해당 페이지까지 수집해오는 함수
def df_set1(begindate, enddate, page_no) :
import pandas as pd
import requests
import json
from pandas.io.json import json_normalize
import time
from tqdm import trange
# 기간 범위 내의 검색결과에서 페이지에 있는 목록 수집해오는 함수
def df_func1(begindate, enddate, page_no) :
'''
기간 범위 내의 검색결과에서 페이지 번호까지의는 목록 수집해온다.
날짜는 '-'없이 연월일 순으로 8자리로 표현하여 작성한다.
예시)
begindate = 20220101
enddate = 20230101
컬럼 : 분야, 제목, 내용, 동의수, 동의률, 동의시작일, 동의마감일, 담당기관, 아이디, 청원결과
'''
url1 = f'https://petitions.assembly.go.kr/api/petits?pageIndex={page_no}&recordCountPerPage=8&sort=AGRE_END_DE-&searchCondition=sj&searchKeyword=&petitRealmCode=&sttusCode=PETIT_FORMATN,CMIT_FRWRD,PETIT_END&resultCode=BFE_OTHBC_WTHDRAW,PROGRS_WTHDRAW,PETIT_UNACPT,APPRVL_END_DSUSE,ETC_TRNSF¬InColumn=RESULT_CODE&beginDate={begindate}&endDate={enddate}&ageCd='
data = {"agreCo" : "",
"agreBeginDe" : "",
"agreEndDe": "",
"jrsdCmitCode": "",
"jrsdCmitNm": "",
"mberId": "",
"petitCn": "",
"petitEndDt": "",
"petitRealmNm": "",
"petitSj": "",
"resultCode": "",
"resultCodeNm": ""
}
response = requests.get(url1, data = data)
jo = json.loads(response.text)
df = json_normalize(jo)
# 원하는 컬럼을 골라 데이터프레임 만듦.
# 컬렁명을 이해하기 쉽게 바꿈.
df = df[[ "petitRealmNm", "petitSj", "petitCn", "agreCo","agreBeginDe","agreEndDe", "jrsdCmitNm", "mberId","resultCodeNm"]]
df.columns = ['분야', '제목', '내용', '동의수', '동의시작일', '동의마감일', '담당기관', 'id', '청원결과']
agree_list = [round((df['동의수'][i] / 50000) *100, 1) for i in range(df['동의수'].count())]
df['동의율(%)'] = agree_list
df = df[[ '분야', '제목', '내용', '동의수', '동의율(%)', '동의시작일', '동의마감일', '담당기관', 'id', '청원결과']]
return df
df_list1 = []
for i in trange(1,page_no +1) :
result1 = df_func1(begindate, enddate, i)
df_list1.append(result1)
time.sleep(0.0001)
return pd.concat(df_list1).reset_index(drop = True)
df_result = df_set1(20220101, 20221231, 3)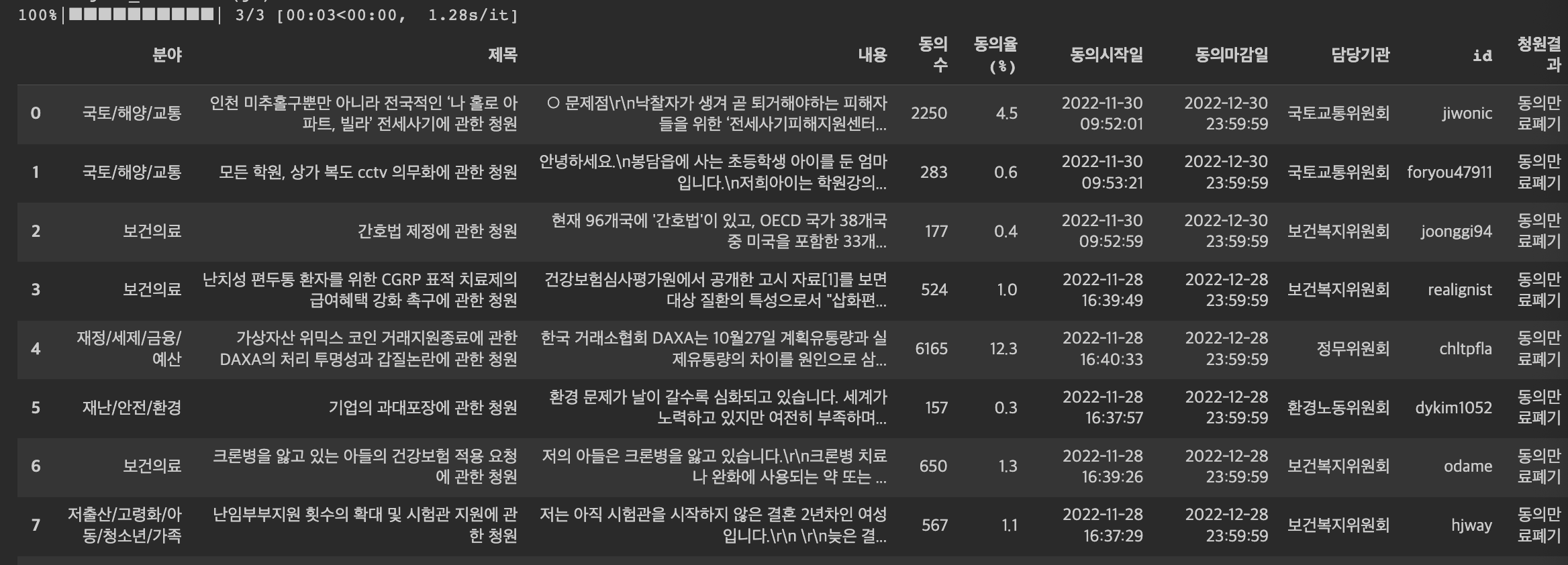
# 분야별 청원결과를 나타냄.
ana = df_set1(20220101, 20221231, 10)
ana_result = ana[['분야', '청원결과', "제목"]].groupby(['분야', '청원결과']).count()
ana_result.to_csv("청원_scrapping_ana.csv", index = True)
pd.read_csv("청원_scrapping_ana.csv")
위에까지는 동의만료된 게시글만 있는 페이지였다. 그래서 동의 진행중인 페이지를 추가로 진행하였다.
두 페이지의 검색 방법이 달라 두 페이지를 불러와 병합는 것을 불가능했다.
동의수를 나와있지만 동의율이 없어 파생컬럼을 만들어주었다. 동의율을 통해 청원이 어떻게 진행되는지 좀 더 직관적으로 볼 수 있게 하기 위함이다.
def df_set2(page_no) :
import pandas as pd
import requests
import json
from pandas.io.json import json_normalize
from tqdm import trange
import time
def df_func2(page_no) :
'''
동의 진행중인 페이지
만료 임박 순으로 검색결과에서 페이지 번호까지의는 목록 수집해온다.
컬럼 : 진행상태, 분야, 제목, 내용, 동의수, 동의률, 동의시작일, 동의마감일, 담당기관, 아이디, 청원결과
'''
url2 = f'https://petitions.assembly.go.kr/api/petits?pageIndex={page_no}&recordCountPerPage=8&sort=PETIT_OTHBC_DT-&searchCondition=sj&searchKeyword=&petitRealmCode=&sttusCode=AGRE_PROGRS&beginDate=&endDate=&ageCd='
data = { "sttusCode" : "",
"agreCo" : "",
"agreBeginDe" : "",
"agreEndDe": "",
"jrsdCmitCode": "",
"jrsdCmitNm": "",
"mberId": "",
"petitCn": "",
"petitEndDt": "",
"petitRealmNm": "",
"petitSj": "",
"resultCode": "",
"resultCodeNm": ""
}
response = requests.get(url2, data = data)
jo = json.loads(response.text)
df = json_normalize(jo)
# 원하는 컬럼을 골라 데이터프레임 만듦.
# 컬렁명을 이해하기 쉽게 바꿈.
df = df[[ "sttusCode","petitRealmNm", "petitSj", "petitCn", "agreCo","agreBeginDe","agreEndDe", "jrsdCmitNm", "mberId","resultCodeNm"]]
df.columns = [ "상태", '분야', '제목', '내용', '동의수', '동의시작일', '동의마감일', '담당기관', 'id', '청원결과']
# 동의율 파생컬럼 생성 : 동의수를 5만명이 기준으로 나누어 백분율로 표현
agree_list = [round((df['동의수'][i] / 50000) *100, 1) for i in range(df['동의수'].count())]
df['동의율(%)'] = agree_list
df = df[[ "상태", '분야', '제목', '내용', '동의수', '동의율(%)','동의시작일', '동의마감일', '담당기관', 'id', '청원결과']]
return df
df_list2 = []
for i in trange(1,page_no +1) :
result2 = df_func2(i)
df_list2.append(result2)
time.sleep(0.0001)
return pd.concat(df_list2).reset_index(drop = True)
df_set2(2)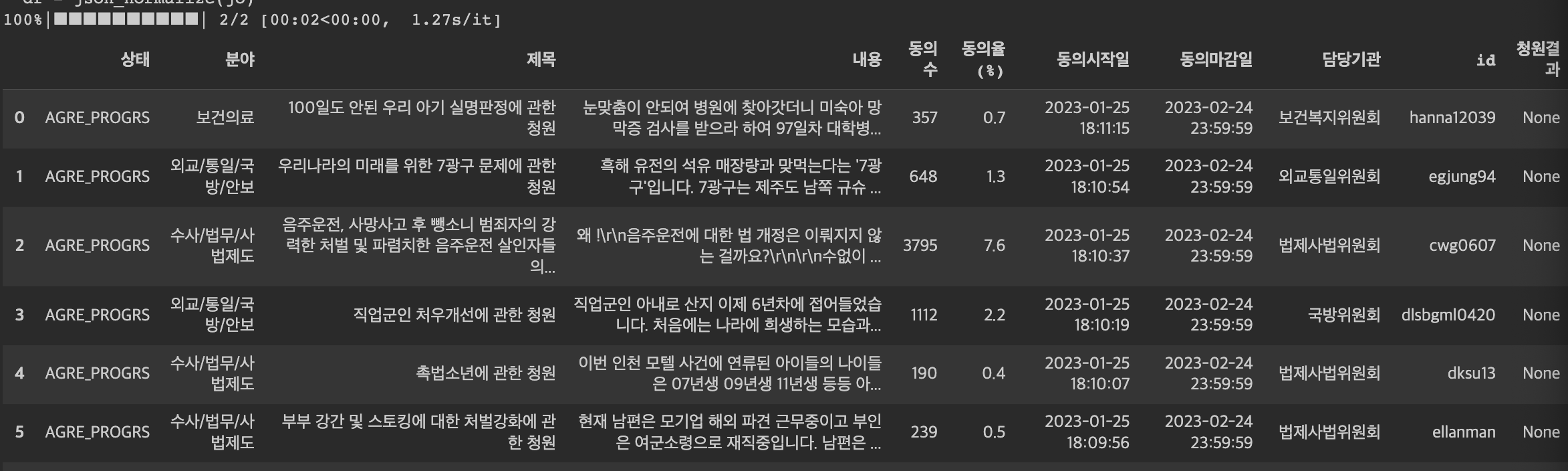
회고
국민청원 스크랩핑을 하며 웹 스크랩핑에 조금 익숙해진 것 같다.
하지만 아직 수집한 내용을 분석하는 데에는 미숙한 것 같다. 불러왔는데 어떻게 해야할지 모르겠다.
분석 능력을 키우고 다시 이 데이터를 본다면 뭔가 유의미한 해석을 할 수 있지 않을까 싶다.
'멋쟁이사자처럼 > Project' 카테고리의 다른 글
| Midproject_(1)_서울시 1인가구 거주지 추천 서비스 (2) | 2023.03.02 |
|---|---|
| Miniproject_(3)_boxoffice (0) | 2023.03.02 |
| Miniproject_(1)_starbucks_API (0) | 2023.03.01 |
'멋쟁이사자처럼/Project' Related Articles
more



Comments