
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 멋재이사자처럼
- paper review
- TiL
- SQL
- Rag
- 파이썬
- DFS
- 인턴10
- 시각화
- 마이온
- ux·ui디자인
- GNN
- 멋사
- 멋쟁이사자처럼
- folium
- Python
- 프로젝트
- Join
- likelion
- 그리디
- parklab
- DP
- BFS
- graphrag
- likelionlikelion
- tog
- 마이온컴퍼니
- seaborn
- intern10
- 알고리즘
Archives
- Today
- Total
지금은마라톤중
Miniproject_(1)_starbucks_API 본문
첫 미니 프로젝트이다.
스타벅스 api를 활용하여 지도에 지역과 매장타입을 입력 받으면 매장의 위치를 마크업하는 함수를 구현하였다.
또한 매장간 거리 차이를 이용하여 상도덕이 없는 매장은 어디인가? 라는 주제로 분석을 해볼려고 했다.
수업에서 계속 csv 파일만 이용하다가 json 형식을 처음 사용해보았다.
불러오는 방식부터 데이터프레임으로 만드는 방법까지 차이가 있어 처음에 당황했다.
불러올 때는 json.load(변수), 데이터프레임으로 만들 때는 json_normalize()를 사용한다.
import pandas as pd
import requests
import json
from pandas.io.json import json_normalize # jsnon을 데이터프레임으로 만들 때 사용
from haversine import haversine # 지점간 거리를 구하는 수학공식 라이브러리
import numpy as np
스타벅스 API는 post방식을 사용하여 불러올 수 있다.
post 방식은 아래 코드와 같이 쿼리 스트링을 dict형태로 변수에 담아 따로 써서 넣어준다.
data = {
"ins_lat": "37.56682", # 위도
"ins_lng": "126.97865", # 경도
"p_sido_cd": "04", # 시도코드
"p_gugun_cd": "",
"in_biz_cd": "",
"iend": "1000",
"set_date" : ""
}
url = 'https://www.starbucks.co.kr/store/getStore.do'
# headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.post(url, data = data)
response.status_code
jo = json.loads(response.text)
df = json_normalize(jo,'list')
df
df.columns
#Index(['seq', 'sido_cd', 'sido_nm', 'gugun_cd', 'gugun_nm', 'code_order',
# 'view_yn', 'store_num', 'sido', 'gugun',
# ...
# 't22', 't21', 'p90', 't05', 't30', 't36', 't27', 't29', 't43', 't48'],
# dtype='object', length=129)# 원하는 컬럼만 추출하여 데이터프레임 만듦
# 한글로 컬럼명 변경
df = df[['s_name', 'lat', 'lot', 'sido_name', 'gugun_name', 'doro_address', 'open_dt']]
df.columns = ["매장명", "위도","경도","도시명","지역구","도로명주소", "오픈일"]
df[:-1]
# 오픈일 컬럼에서 오픈연도 파생컬럼 만듦
df['오픈연도']=pd.DatetimeIndex(df["오픈일"]).year
df
# 반복문을 활용하여 매장명에서 매장타입을 추출
# 매장명에서 DT인 매장을 구분하여 새로운 컬럼으로 추가해줌.
dt_list= []
for i in df['매장명'] :
if i[-2:] == 'DT' :
dt_list.append("DT 매장")
elif i[-1:] =="R" :
dt_list.append("R 매장")
else :
dt_list.append("일반 매장")
df_dt = pd.DataFrame(dt_list)
df['매장종류'] = df_dt
df

# 도로명 주소에서 동이름 분리하여 새로운 컬럼으로 추가해줌.
# 동이름이 두글자나 네글자인 것이 있어 슬라이싱을 사용하면 정확히 분리를 못한다.
# 리스트 컴프리핸션을 사용
dong_list= df["도로명주소"]
dong_name = []
lst = [ i.split("(")[-1] for i in list(dong_list)] # 도로명 주소에서 "(" 기준으로 나누고 뒤에 것만 분리
lst = [ i.split(")")[0] for i in lst] # 도로명 주소에서 ")" 기준으로 나누고 앞에 것만 분리
for i in lst :
if i[-1] == "동" :
dong_name.append(i)
else :
dong_name.append("-")
df['동이름'] = do
도시명 입력 시 스타벅스 매장 df 보여주는 함수 구현
def df_city_store(city) :
# 도시명을 입력하면 해당 도시에 있는 스타벅스 매장에 대한 데이터프레임 출력
# 컬럼 : 매장명, 위도, 경도, 도시명, 지역구, 도로명주소, 오픈일, 오픈연도, 매장종류, 동이름
import pandas as pd
import requests
import json
from pandas.io.json import json_normalize
import folium
code = {'전체' : '00', '서울' : '01', '광주' : '02', '대구' : '03',
'대전' : '04', '부산' : '05', '울산' : '06', '인천' : '07',
'경기' : '08', '강원' : '09', '경남' : '10', '경북' : '11',
'전남' : '12', '전북' : '13', '충남' : '14', '충북' : '15',
'제주' : '16', '세종' : '17'}
data = {
"ins_lat": "37.56682",
"ins_lng": "126.97865",
"p_sido_cd": code[city],
"p_gugun_cd": "",
"in_biz_cd": "",
"iend": "1000",
"set_date" : ""
}
url = 'https://www.starbucks.co.kr/store/getStore.do'
# headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.post(url, data = data)
response.status_code
jo = json.loads(response.text)
df = json_normalize(jo,'list')
df = df[['s_name', 'lat', 'lot', 'sido_name', 'gugun_name', 'doro_address', 'open_dt']]
df.columns = ["매장명", "위도","경도","도시명","지역구","도로명주소", "오픈일"]
df['오픈연도']=pd.DatetimeIndex(df["오픈일"]).year
# 매장명에서 DT인 매장을 구분하여 새로운 컬럼으로 추가해줌.
dt_list= []
for i in df['매장명'] :
if i[-2:] == 'DT' :
dt_list.append("DT 매장")
elif i[-1:] =="R" :
dt_list.append("R 매장")
else :
dt_list.append("일반 매장")
df_dt = pd.DataFrame(dt_list)
df['매장종류'] = df_dt
# 도로명 주소에서 동이름 분리하여 새로운 컬럼으로 추가해줌.
# 동이름이 두글자나 네글자인 것이 있어 슬라이싱을 사용하면 정확히 분리를 못한다.
dong_list= df["도로명주소"]
dong_name = []
lst = [ i.split("(")[-1] for i in list(dong_list)] # 도로명 주소에서 "(" 기준으로 나누고 뒤에 것만 분리
lst = [ i.split(")")[0] for i in lst] # 도로명 주소에서 ")" 기준으로 나누고 앞에 것만 분리
for i in lst :
if i[-1] == "동" :
dong_name.append(i)
else :
dong_name.append("-")
df['동이름'] = dong_name
return df
df_city_store('대전')연도별 오픈된 대전 스타벅스 매장 갯수
- 스타벅스가 DT매장을 본격화한 것은 15년도 이후/R매장은 17~19년도에 집중적으로 진행
- 일반 매장이 특별 매장 대비 10배 이상 많음
yr_type = pd.crosstab(index=df.매장종류, columns=df.오픈연도, values=df.매장명, aggfunc=np.size, margins=True).fillna(0)
yr_type = yr_type.astype(int)
yr_type.style.background_gradient(cmap='coolwarm')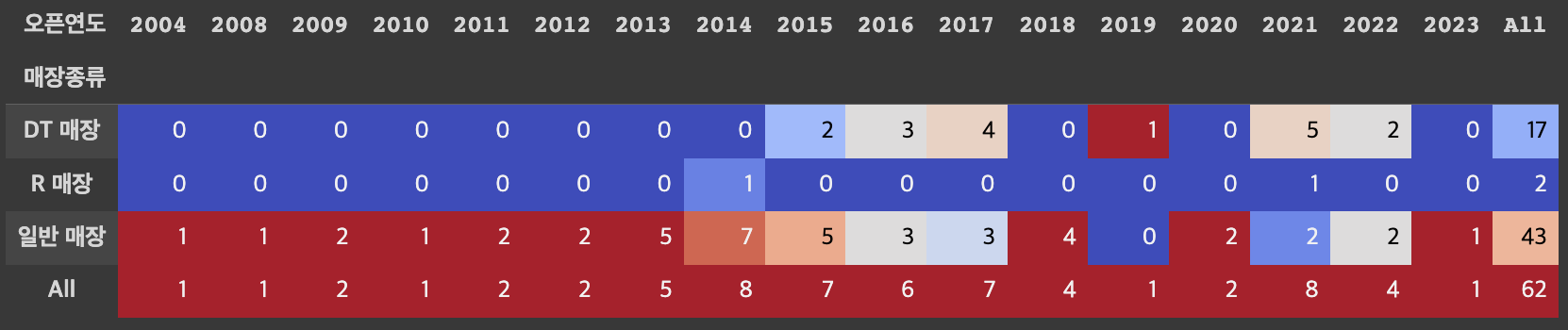
지도 시각화
지도 시각화를 위해 위경도의 데이터타입을 실수로 변경하였다.
# 위도와 경도의 타입을 문자열 > 실수로 변경
df['위도'] = df['위도'].astype(float)
df['경도'] = df['경도'].astype(float)# 지리정보 시각화 모듈을 통해 대전엑스포스카이 지점 위치 확인
expo_point = (36.37514, 127.38161)
import folium
map_expo = folium.Map(location=(expo_point), zoom_start = 17 )#tiles = 'Stamen Toner'
folium.Marker(expo_point, popup = '엑스포').add_to(map_expo)
map_expo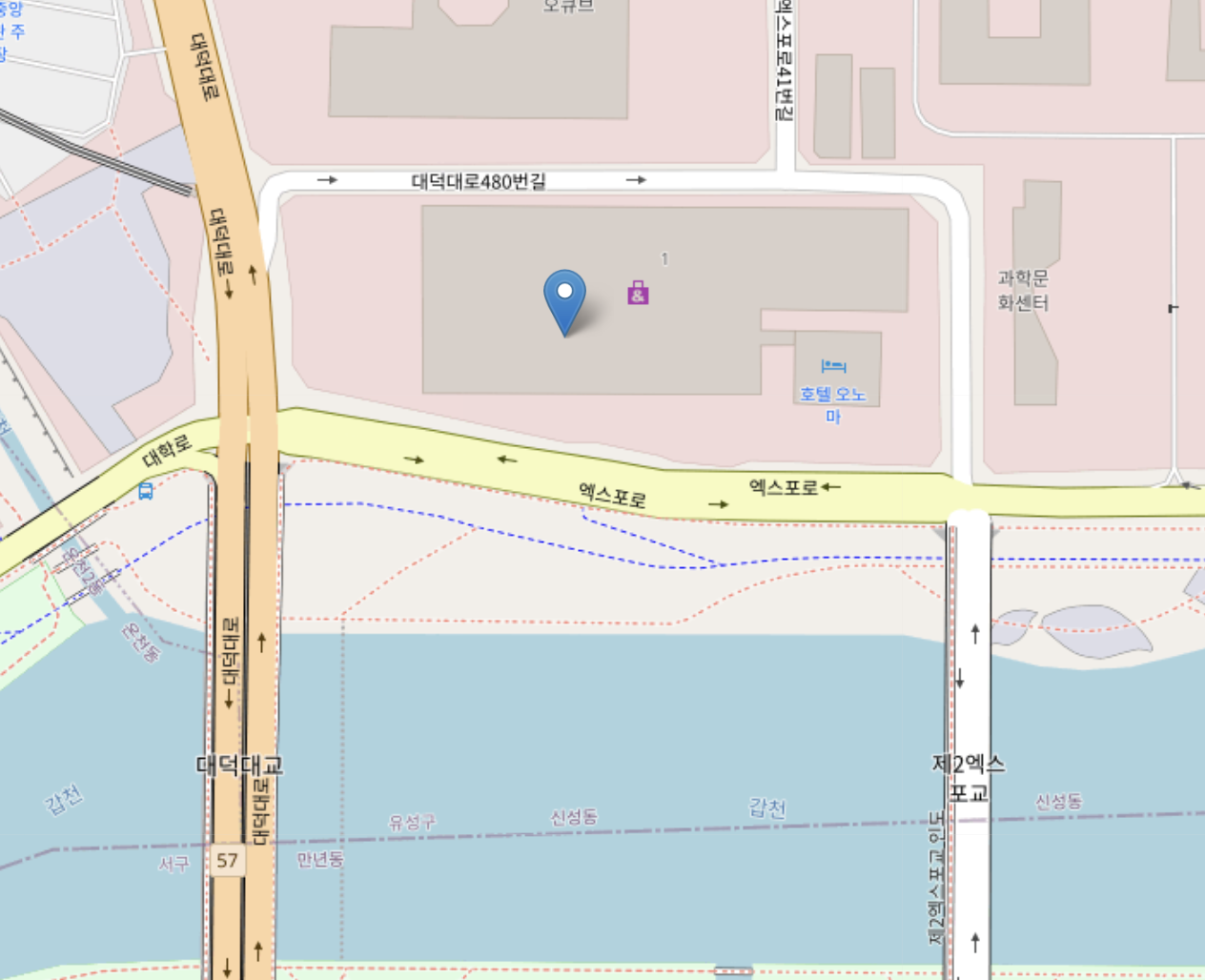
# DT 매장만 골라서 지도에 마커를 표시하고 마커 이름은 매장이름으로 설정
dt_loc = (36.350191, 127.405652)
map_dt = folium.Map(location=(dt_loc), zoom_start = 11) #tiles = 'Stamen Toner'
for ix, row in df.iterrows():
if row['매장종류'] == "DT 매장":
location = (row['위도'], row['경도'])
folium.Marker(location, popup = row['매장명']).add_to(map_dt)
map_dt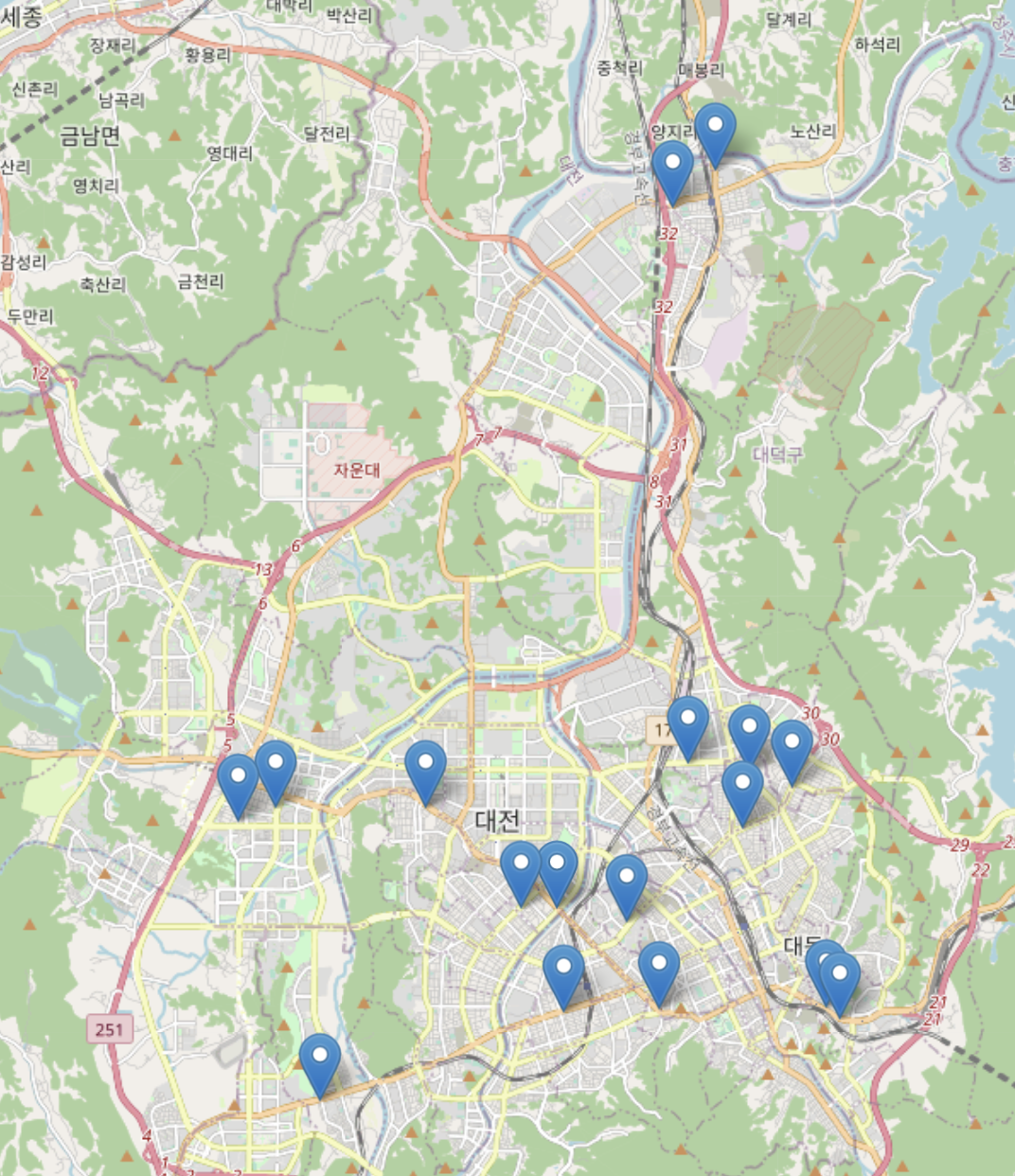
도시명과 매장타입 입력하면 지도 시각화해주는 함수 구현
# 지역이름과 매장타입을 쓰면 지역 내 해당 매장들의 위치가 마크업되어 지도를 보여주는 함수 만듦.
# 매장타입별 함수 정의를 하나로 합쳐 깔끔하게 정리
# 함수의 파라미터? store_type > store로 바꿈, df의 컬럼 store_type과 구분하기 위함
def see_store_re(city, store = '일반 매장') :
import pandas as pd
import requests
import json
from pandas.io.json import json_normalize
import folium
code = {'전체' : '00', '서울' : '01', '광주' : '02', '대구' : '03',
'대전' : '04', '부산' : '05', '울산' : '06', '인천' : '07',
'경기' : '08', '강원' : '09', '경남' : '10', '경북' : '11',
'전남' : '12', '전북' : '13', '충남' : '14', '충북' : '15',
'제주' : '16', '세종' : '17'}
data = {
"ins_lat": "37.56682",
"ins_lng": "126.97865",
"p_sido_cd": code[city],
"p_gugun_cd": "",
"in_biz_cd": "",
"iend": "1000",
"set_date" : ""
}
url = 'https://www.starbucks.co.kr/store/getStore.do'
# headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.post(url, data = data)
response.status_code
jo = json.loads(response.text)
df = json_normalize(jo,'list')
df = df[['s_name', 'lat', 'lot', 'sido_name', 'gugun_name', 'doro_address']]
df.columns = ["매장명", "위도","경도","도시명","지역구","도로명주소"]
# 매장명에서 DT인 매장을 구분하여 새로운 컬럼으로 추가해줌.
dt_list= []
for i in df['매장명'] :
if i[-2:] == 'DT' :
dt_list.append("DT 매장")
elif i[-1:] =="R" :
dt_list.append("R 매장")
else :
dt_list.append("일반 매장")
df_dt = pd.DataFrame(dt_list)
df['매장종류'] = df_dt
df['위도'] = df['위도'].astype(float)
df['경도'] = df['경도'].astype(float)
def markup_st_store(city) :
# df에서 해당 매장만 추출하면 새로운 데이터프레임 만듦
# df2에서 위도,경도의 평균치를 이용하여 해당 매장만 지도에 표시했을 때 화면이 정가운데에 위치하게 만들 예정
df2 = df.loc[df['매장종류']== store]
# df2.describe()로 평균치 구함
mean_st_loc = { 'lat' : df2['위도'].mean(), 'lot' : df2['경도'].mean()}
# 해당 매장만 골라서 지도에 마커를 표시하고 마커 이름은 매장이름으로 설정
# dt_loc 는 dt 매장들의 위도, 경도의 평균값을 사용하여 지도에 모든 매장이 보이기 편하도록 설정
st_loc = (mean_st_loc['lat'], mean_st_loc['lot'])
map_st = folium.Map(location=(st_loc), zoom_start = 11) #tiles = 'Stamen Toner'
for ix, row in df.iterrows():
if row['매장종류'] == store :
location = (row['위도'], row['경도'])
folium.Marker(location, popup = row['매장명']).add_to(map_st)
return map_st
return markup_st_store(city)
see_store_re('광주', 'DT 매장')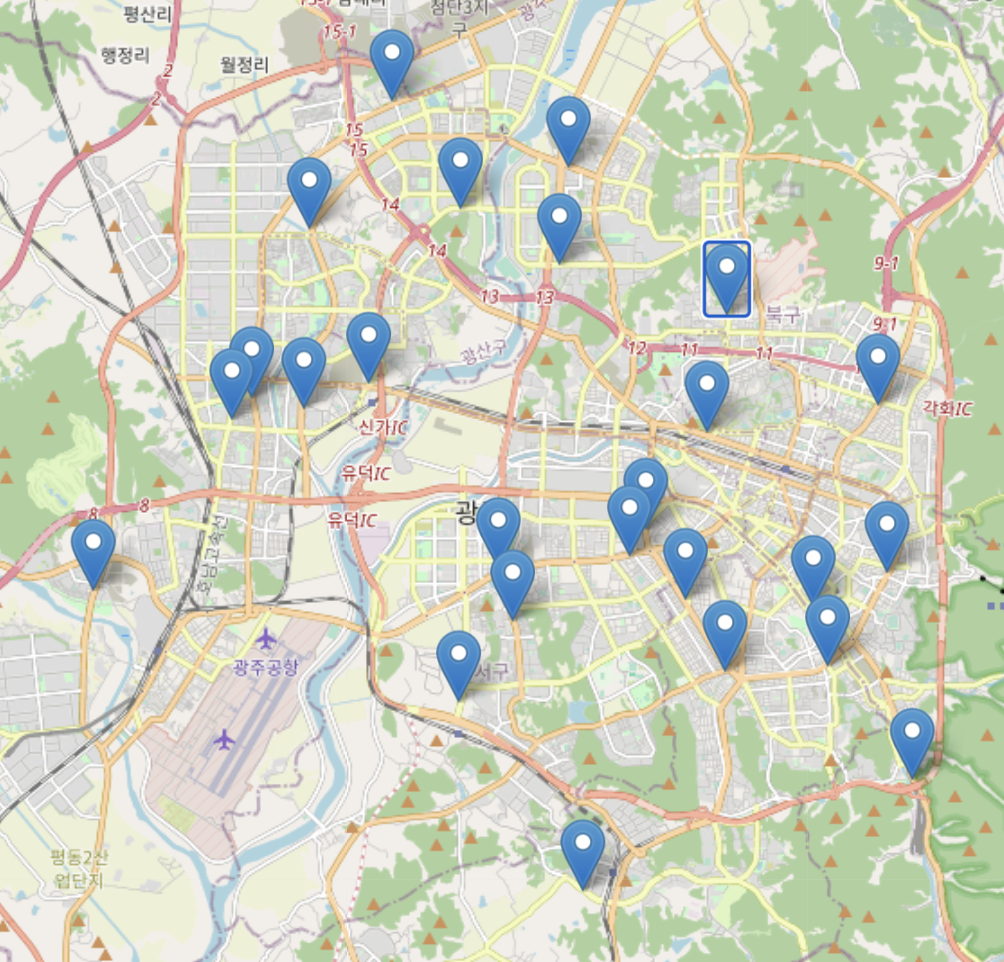
매장간 거리 구하기
haversine 라이브러리 사용
# 거리차이만 테이블 출력!!
# 위도와 경도의 타입을 문자열 > 실수로 변경
df = df.astype({'위도' : 'float'})
df = df.astype({'경도' : 'float'})
# 지점 사이의 거리 구하는 방법 haversine 사용!
dis_store_list = []
lst_dis_total = []
i = 0
while True :
standard_store = (df['위도'][i], df['경도'][i])
for a, b in zip(df['위도'][i+1:], df['경도'][i+1:]) :
other_store = (a, b)
stor_to_stor_dis = haversine(standard_store, other_store)
store_lst = [df['매장명'][i], df[df['위도'] == a]['매장명'], round(stor_to_stor_dis * 1000, 2)]
dis_store_list.append(store_lst)
if i == df.shape[0] - 1 :
break
i +=1
# # 매장에 따른 주변매장과의 거리차이를 데이터프레임으로 만듦
df_dis = pd.DataFrame(dis_store_list)
df_dis.columns = ["매장명", "주변매장", "거리차이(m)"]
df_dis = df_dis.sort_values("거리차이(m)", ascending = True)
df_dis
# 주변매장에서 매장이름만 분리해내기 위해 진행
df_dis['주변매장'] = df_dis['주변매장'].astype(str)
df_dis["주변매장"] = df_dis.주변매장.str.split(" ").str[4]
df_dis["주변매장"] = df_dis.주변매장.str.split("\n").str[0]
df_dis = df_dis[4:]
df_dis
회고
일반 프랜차이즈 매장의 경우 매장간 일정 거리가 지켜져야한다는 규칙이 있어 이걸 바탕으로 주제를 잡았는데 스타벅스의 경우 모든 매장이 직영점이라 거리차이가 필요없다. 오히려 가까운 곳에 매장이 있을 경우 각 매장 매출은 줄 수 있지만 전체 매출을 오른다는 사실을 분석 막바지에 알게되었다.
재밌있는 주제라고 생각하여 처음 진행하는 프로젝트여서 많이 막혔지만 재미있게 할 수 있었다.
하지만 스타벅스의 정책에 대한 조사를 제대로 하지 못하고 분석을 진행한 점에 있어 분석을 할 때 도메인에 대한 충분한 이해와 지식이 필요하다는 사실을 상기시킬 수 있었다.
'멋쟁이사자처럼 > Project' 카테고리의 다른 글
| Midproject_(1)_서울시 1인가구 거주지 추천 서비스 (2) | 2023.03.02 |
|---|---|
| Miniproject_(3)_boxoffice (0) | 2023.03.02 |
| Miniproject_(2)_국민청원_scrapping (0) | 2023.03.01 |
'멋쟁이사자처럼/Project' Related Articles
more



Comments