
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- ux·ui디자인
- likelionlikelion
- Python
- TiL
- seaborn
- 마이온
- paper review
- 파이썬
- Join
- tog
- 멋사
- 멋재이사자처럼
- 그리디
- 시각화
- BFS
- 멋쟁이사자처럼
- likelion
- DFS
- 마이온컴퍼니
- 인턴10
- folium
- DP
- 알고리즘
- SQL
- Rag
- graphrag
- parklab
- 프로젝트
- GNN
- intern10
- Today
- Total
지금은마라톤중
[Paper Review] Graphusion 본문
Graphusion
: A RAG Framework for Scientific Knowledge Graph Construction
with a Global Perspective
0. Abstract
지식그래프(KG)는 인공지능과 QA(Question-answering)과 같은 downstream task에서 중요한 역할을 하고 있습니다. 이런 KG를 구축하는데에는 전문가들의 상당한 노력을 필요로 합니다. 최근에 LLM이 지식 그래프 구축(KGC)에 사용되고 있습니다. 그러나, 대부분의 기존 접근들은 지역적 관점에서 지식 트리플을 추출하기에 전역적인 관점을 잃게됩니다.
해당 논문에서는 free text로부터의 zero-shot KGC framework인 ‘Graphusion’을 제안합니다.
총 3단계로 구성되어 있으며 : Step 1에서는 토픽 모델링을 통해 관련한 시드 엔티티를 추출합니다 ; Step2에서는 LLM을 활용해 후보 트리플들을 추출합니다; Step3에서는 새로운 fusion module을 통해 추출한 지식들에 전역적 관점을 제공합니다.
또한, TutorQA라는 전문가 검증된 새로운 QA benchmark를 소개합니다.
1. Introduction
최근 몇 년 사이 Retrieval-Augmented Generation (RAG) 기법이 빠르게 발전하면서,
단순한 텍스트 생성 이상의 지식 기반 질의응답(QA)이나 요약 작업에서도 높은 성능을 보여주고 있습니다.
기존 RAG는 대부분 단일 문서 또는 단편적인 문맥(local context)을 기반으로 작동하기 때문에,
다음과 같은 한계가 존재합니다.
- 과학 도메인과 같이 계층적인 개념이 얽혀 있는 분야에서는 단편적인 triplet 추출만으로는 불충분
- 서로 다른 문서에 흩어진 개념 간 관계를 파악하지 못함
- 전역적인 구조 없이 Disconnected Sub-KGs만 생성됨
- 엔티티 중복, 관계 충돌, 세분화 부족 문제

위 그림은 기존의 방식들과 Graphusion의 차이를 직관적으로 보여줍니다:
| Zero-shot LLM | 전체 지식 없이 LLM에만 의존 | 과도하게 일반적이거나 불명확한 개념 생성 |
| Local Graph-RAG | 검색 기반으로 triplet 추출 | Subgraph만 생성되고 전체 구조 파악 불가 |
| GraphRAG | 계층적 그래프를 생성하고 요약 | 높은 계산 비용, 관계 충돌 미해결 |
| Graphusion | Seed 엔티티 기반 추출 + 전역 Fusion 수행 | 연결성, 세분성, 일관성 모두 고려 |
2. Graphusion: Zero-shot Knowledge Graph Construction
Graphusion은 기존 방식의 한계를 해결하기 위해 다음 두 가지를 결합합니다 :
1. LLM 기반 Zero-shot Triplet 추출
2. Knowledge Graph Fusion을 통한 전역 통합
특히, 기존 GraphRAG와는 달리:
- 관계 충돌 해결(conflict resolution)
- 유사 엔티티 병합(entity merging)
- 새로운 관계 생성(novel triplet inference)
이로써, Graphusion은 과학 지식의 전반적인 구조를 포착합니다.
Graphusion Framework
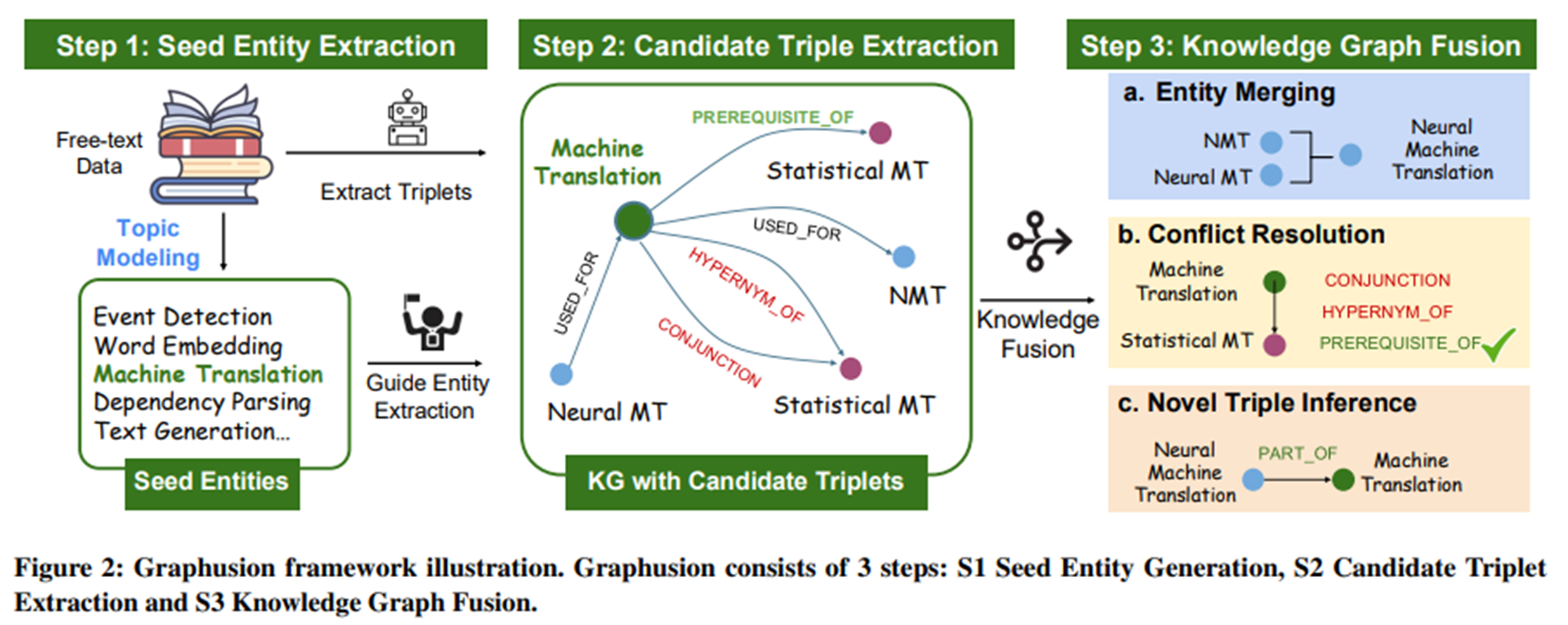
핵심 프로세스
Step1 : Topic modeling을 통해 도메인에 맞는 Seed entities 추출
Step2 : 7개의 relation으로 후보 트리플 추출
Step3 : Entity merging + Conflict Resolution + Novel Triple Inference
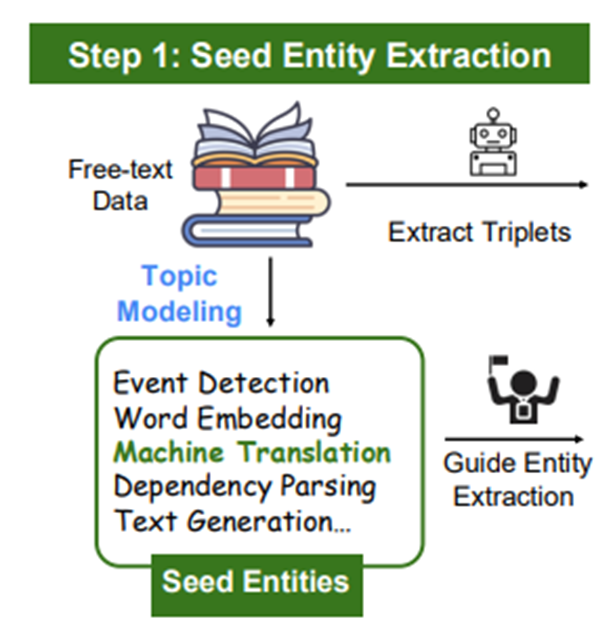
Step1 : Seed Entities Extraction
- BERTopic 모델을 활용하여 in-domain 엔티티 추출
- zero-shot LLM
- Predefined entity list 없어 무관한 엔티티 추출하는 경향이 크기 때문
Step2 : Candidate Triples Extraction
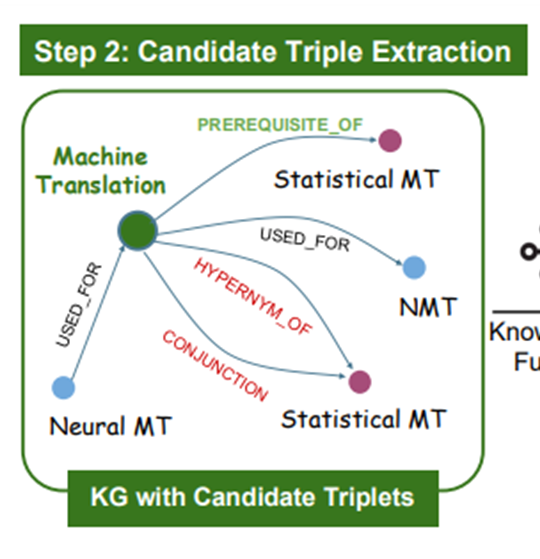
- CoT Prompt로 Seed Entity와 관련한 트리플 추출
- Relation을 7개로 강제
- novel triplets을 추출
- Retrieved docs에서 추출
- 문맥 기반의 확장된 추출


| Relation type | 예시 |
| Prerequisite_of | A는 B를 이해하기 위한 전제 조건 |
| Used_for | A는 B를 수행하는 데 사용됨 |
| Compare | A와 B는 비교 가능한 개념 |
| Conjunction | A와 B는 함께 사용됨 |
| Hyponym_of | A는 B의 하위 개념 |
| Evaluate_for | A는 B의 평가 지표로 사용됨 |
| Part_of | A는 B의 구성 요소 |
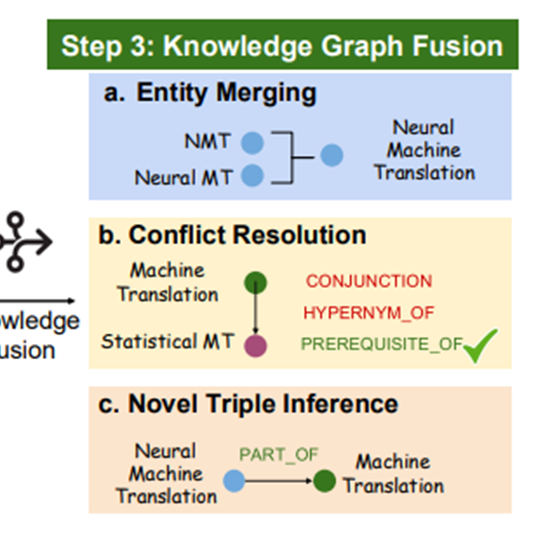
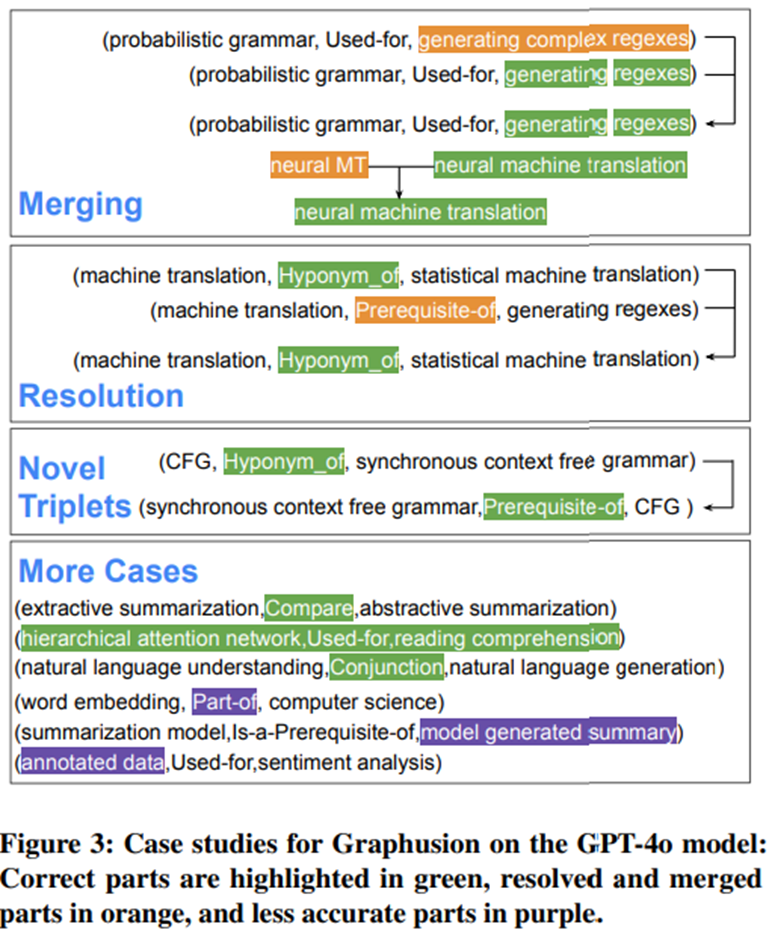
Step3 : Knowledge Graph Fusion
- 엔티티 병합 : 유사한 의미의 엔티티 병합
- 충돌 해결 : {background}를 넣어줘서 충돌해결의 이해를 도움
- novel triple 추출
- background에서 추출
case study : fusion step
3. Experiments
Experiments Setting
Dateset
- ACL 학술 논문(2017-2023) (총 4,605 논문)
- 논문의 초록만 활용하여 고밀도 정보 반영
Baselines
- different LLMs: LLaMa3-70b3 , GPT-3.5, GPT-4 and GPT-4o.
- zero-shot (GPT-4o zs) and RAG (GPT-4o RAG)
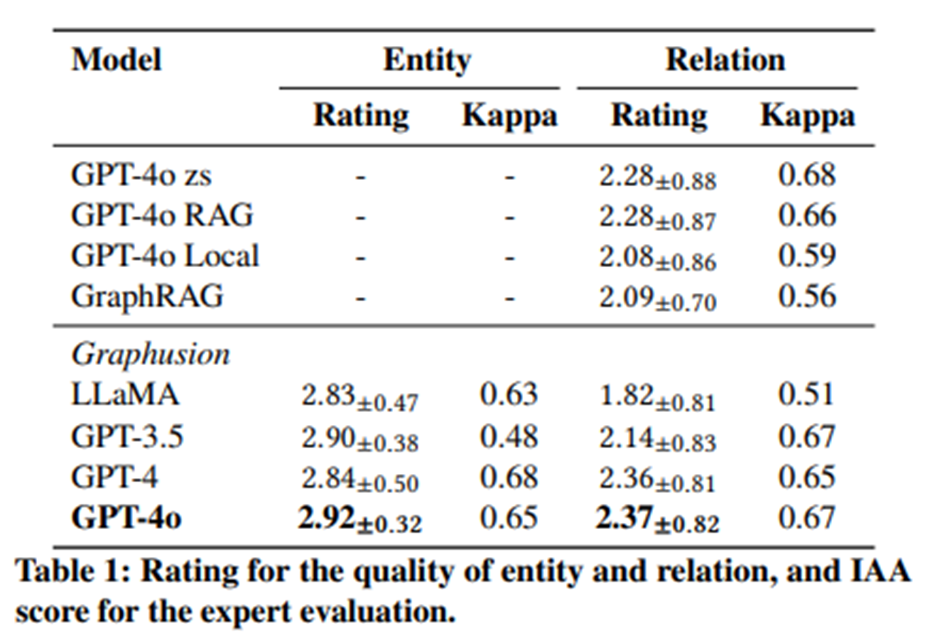
Graph Evaluation Metrics
- 인간 평가(전문가)
- 샘플 100개의 트리플 랜덤하게 추출
- 1(bad) ~ 3(good)으로 평가
- Entity and Relation Quality 평가
- Kappa Score : 0.6 이상이면 상당한 일치도
Link Prediction Experiments
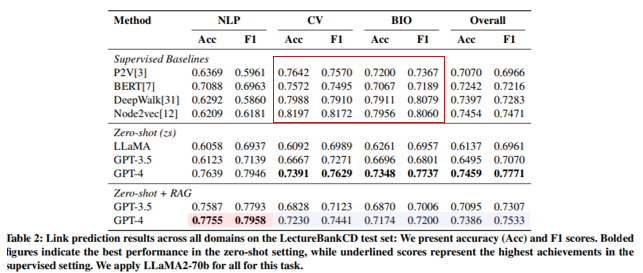
- LectureBankCD 활용
- Relation : Prerequisite_of만 예측
- GPT-4 zs가 성능이 대체로 좋음
- RAG 활용
- NLP에서는 zero-shot 대비 성능 향상
- CV와 BIO에서는 성능 저하
→ RAG 데이터셋이 NLP로 이루어져 있기 때문
4. TutorQA Benckmark
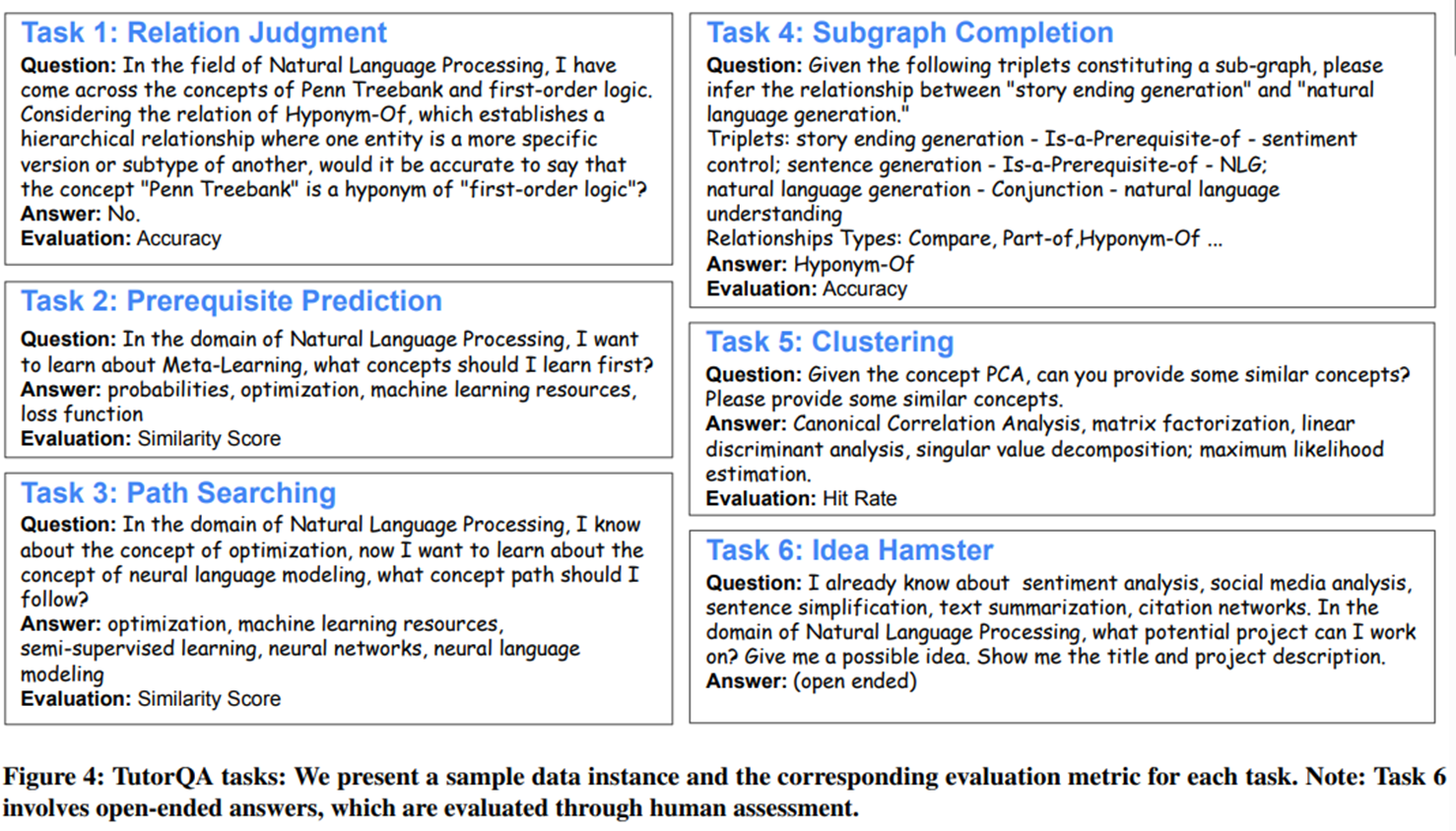
- 6개의 task
- Answer Type : Y/N, Entity list, Open ended
- Eval :
- T1~T5 : Accuracy, Similarity, Hits
- T6 : 2 NLP Expert Evaluation(Kappa score 0.67)
- Relavancy, Coverage, Convincity, Factuality
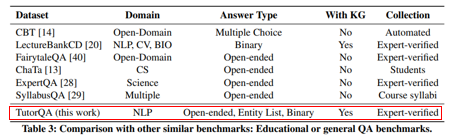
TutorQA Result
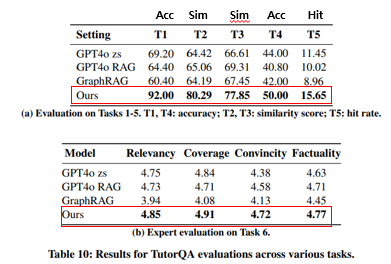
(a) 결과
- Graphusion이 모든 태스크에서 성능 좋음.
- T4(Subgraph Completion), T5(Clustering)을 통해 전역적 이해를 평가 → Step3(Fusion step)의 중요성을 시사
- GraphRAG가 T5에서 성능이 최하
- 너무 보편적이거나 너무 구체적인 용어 생성 → Step1의 중요성 시사, seed 추출 시 세분화의 중요성 시사
(b) 결과
- Graphusion이 T6의 모든 평가에서 제일 높은 점수를 받음
- Convincity and Factuality의 결과를 통해 더 사실적으로 정확할 뿐 아니라 설득력있는 콘텐츠 생성을 시사
case study : Task6

Ablation Study
Prompt별 비교
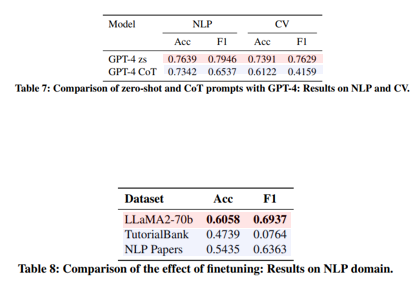
- 성능 : zero-shot > CoT
- CoT가 negative prediction이 더 많이 발견
→ Graphusion의 억제된 환경이 악영향을 작용
Finetuning별 비교
- 2개의 파인튜닝 결과가 더 안 좋게 나옴
- 잠재적 이유
- 안 좋은 데이터의 질
- 그래프 복구 작업을 돕는 효율성 제한
Entity count
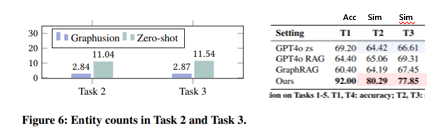
- Graphusion이 zero-shot보다 엔티티를 덜 사용하면서 더 좋은 성능을 냄.
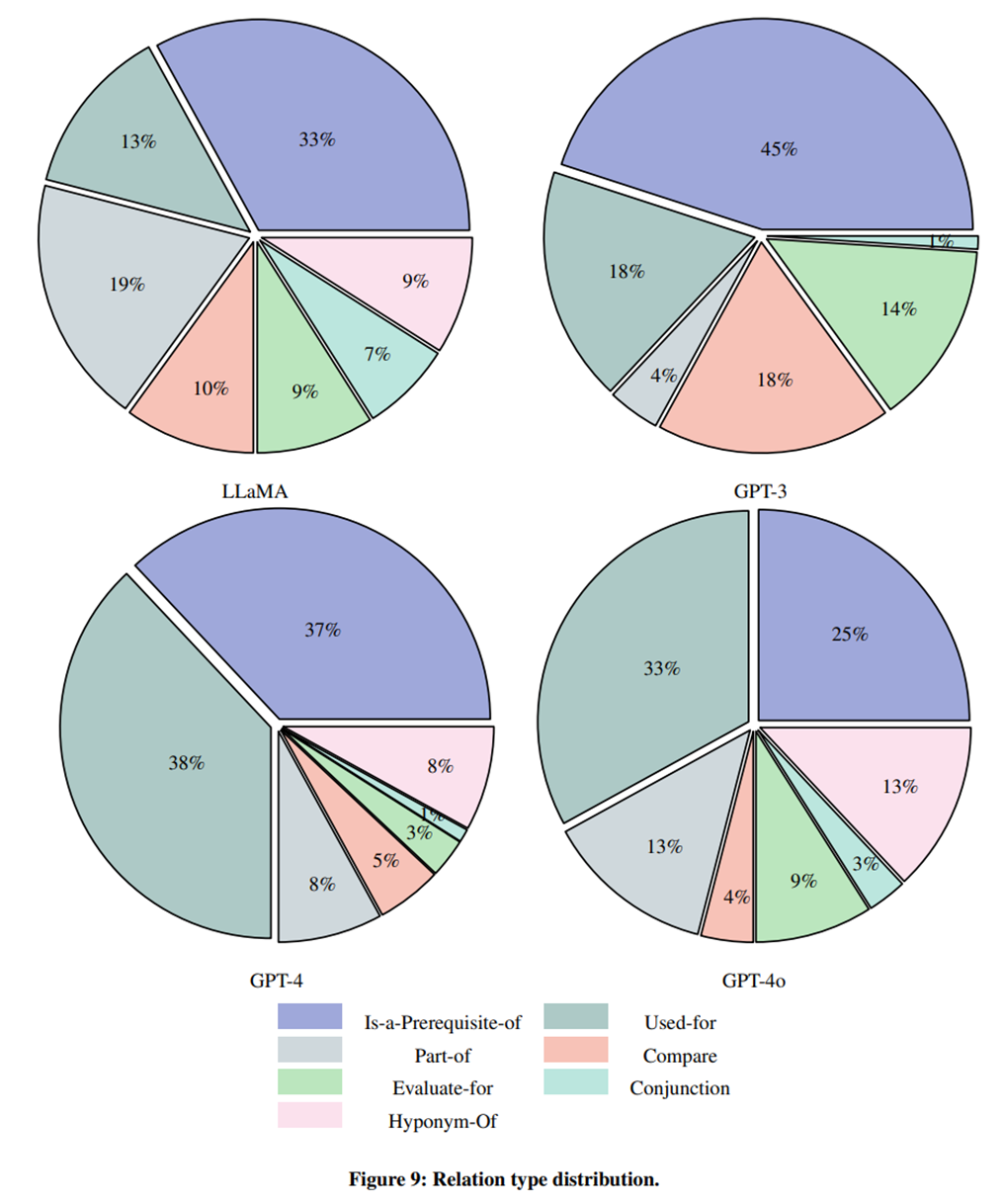
Backbone별 Relation 분포
- Backbone별 7개의 relation의 분포가 다름
- LLM에 따른 결과 차이가 큼을 시사
Insight
- NLP 특히, 교육 도메인에 특화시켜 relation을 7개로 강제한 부분이 성능을 높였지만, 어느정도 한계점으로 작용하여 관계의 표현력이 부족하다고 느꼈습니다.
- relation이 LLM마다 분포 차이가 있어 LLM의 성향에 의존적입니다.
- Zero-shot이 CoT보다 더 성능이 높게 나온 결과를 통해
- 앞서 리뷰한 ToG-2와 같은 단계적인 추론(or iterative) 과정보다 잘 짜여진 KG 구축이 더 우선시되어야하는 것을 시사합니다.
- Step3에서의 Entity Merging, Conflict Resolution, Novel Triple Inference의 각 영향력 평가가 없습니다.
→ KGC의 필요성을 확인할 수 있었습니다. 검색단계만큼인데 KGC가 성능에 튼 영향을 미칩니다. 해당 논문에서는 전역적 관점을 가지는 KG를 구축했다고 했는데 결과에서 mutli-hop 성능을 본 결과를 보지 못해 아쉽습니다. 또한 핵심 단계인 fusion단계에서의 각 기능의 영향력 또한 확인했으면 더 좋은 타당성을 가졌을 것 같습니다. 마지막으로 relation을 NLP도메인에 맞춰 7개로 강제하여 성능은 높였지만 도메인 확장적 측면에서는 부족한 결과를 볼 수 있었습니다.
도메인 일반화를 하는 통합적인 KGC연구가 하나의 연구 방향성이 될 수 있을 것 같습니다.



