

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- parklab
- ux·ui디자인
- 프로젝트
- DFS
- GNN
- TiL
- 알고리즘
- Rag
- folium
- Join
- likelionlikelion
- SQL
- Python
- 멋쟁이사자처럼
- 멋재이사자처럼
- 파이썬
- 시각화
- intern10
- 그리디
- 멋사
- paper review
- graphrag
- BFS
- tog
- 마이온
- seaborn
- 마이온컴퍼니
- likelion
- 인턴10
- DP
- Today
- Total
지금은마라톤중
[Paper review] THINK-ON-GRAPH: DEEP AND RESPONSIBLE REASONING OF LARGE LANGUAGE MODEL ON KNOWLEDGE GRAPH 본문
[Paper review] THINK-ON-GRAPH: DEEP AND RESPONSIBLE REASONING OF LARGE LANGUAGE MODEL ON KNOWLEDGE GRAPH
Ojungii 2025. 1. 21. 12:48THINK-ON-GRAPH: DEEP AND RESPONSIBLE REASONING OF
LARGE LANGUAGE MODEL ON KNOWLEDGE GRAPH
0. 초록 (Abstract)
대형 언어 모델(LLMs)의 한계와 새로운 가능성
대형 언어 모델(LLMs)은 놀라운 자연어 처리 성능을 보여왔지만, 복잡한 추론 문제에서는 여전히 한계를 보이고 있습니다. 특히, 지식이 부족하거나 오래된 경우 hallucination 문제를 일으키며, 추론 과정에서 투명성과 책임감이 부족한 모습을 보입니다. 이러한 문제를 해결하기 위해 지식 그래프(Knowledge Graph, KG)를 활용하는 방법론이 주목받고 있습니다.
ToG(Think-on-Graph): LLM과 KG의 긴밀한 통합
기존에는 LLM이 질문을 SPARQL 쿼리 등으로 변환하여 KG를 질의하는 방식(LLM⊕KG)을 사용했습니다. 하지만, 이는 KG의 품질과 완전성에 따라 성능이 제한되었습니다. ToG(Think-on-Graph)는 이와 달리 LLM이 KG 탐색과 추론 과정에 직접 참여하도록 설계된 알고리즘입니다. 이 방식은 "LLM⊗KG" 패러다임을 기반으로 하며, KG와 LLM이 추론 과정에서 상호 보완적으로 작동합니다.
주요 기여
- 깊은 추론(Deep Reasoning):
- KG에서 다중 홉(Multi-hop) 추론 경로를 탐색하여 LLM의 추론 성능 강화.
- 책임감 있는 추론(Responsible Reasoning):
- 추론 과정에서 사용된 경로를 명시적으로 제공하여 투명성과 신뢰성 확보.
- 플러그 앤 플레이(Flexibility):
- 추가 학습 없이 다양한 LLM과 KG에 적용 가능.
- 작은 모델(LLaMA-2-70B)도 대형 모델(GPT-4)과 경쟁 가능한 성능을 발휘.
- 비용 효율성(Cost Efficiency):
- ToG는 훈련이 필요하지 않아 LLM 운영 및 업데이트 비용을 절감.
1. 서론 (Introduction)
LLM의 현재 한계와 문제점
대형 언어 모델(LLMs)은 다양한 자연어 처리 작업에서 놀라운 성능을 보여주고 있지만, 복잡한 지식 추론 작업에서는 여전히 많은 한계를 보입니다. 특히, 다음과 같은 문제가 자주 지적됩니다:
- 부정확한 지식 및 오래된 정보
- LLM은 사전 학습 데이터에 포함되지 않은 정보에 대해 부정확하거나 잘못된 답변을 제공합니다.
- ex) 최신 지식이나 다중 논리적 연결이 필요한 작업에서는 실패
- 책임감 및 설명 가능성 부족
- LLM이 생성한 답변은 근거가 불명확하며, 학계와 산업계에서 중요한 출처를 제공하지 못합니다.
- 이러한 한계는 특히 의료, 법률 등 신뢰가 필수적인 분야에서 심각한 문제를 야기할 수 있습니다.
- 높은 학습 비용과 업데이트 비효율성
- LLM을 최신 상태로 유지하기 위한 추가 학습은 막대한 비용이 필요하며, 이로 인해 운영 효율성이 저하됩니다.
지식 그래프(KG)의 가능성과 기존 접근법의 한계
지식 그래프(Knowledge Graph, KG)는 체계적이고 명시적으로 지식을 표현하며, LLM의 이러한 한계를 극복할 잠재력을 가지고 있습니다. 연구자들은 KG를 활용하여 LLM의 hallucination 문제를 완화하는 방법을 모색해 왔습니다.
- 기존의 LLM⊕KG 접근법
- LLM이 질문을 SPARQL 쿼리 등으로 변환한 후, KG에서 정보를 검색하여 답변을 생성.
- 하지만 이 방식은 KG의 완전성과 품질에 지나치게 의존하며, LLM은 단순히 명령을 전달하는 "번역기" 역할만 합니다.
- 관계 정보가 누락되거나 KG의 데이터가 불완전할 경우, 답변 생성이 실패할 가능성이 큽니다.
ToG(Think-on-Graph): 새로운 접근법
이 논문에서는 기존의 한계를 극복하기 위해, LLM과 KG를 긴밀히 결합하는 새로운 패러다임인 LLM⊗KG(ToG)를 제안합니다.
- LLM이 추론에 직접 참여
- LLM이 KG에서 관련 엔티티와 관계를 탐색하며, 추론 과정에 능동적으로 관여합니다.
- 이를 통해 단순한 질의-응답을 넘어 복잡한 다중 홉(Multi-hop) 추론이 가능합니다.
- 추론 과정의 유연성과 설명 가능성 강화
- LLM이 탐색한 경로를 명시적으로 기록하여, 모델의 답변에 대한 투명성을 확보합니다.
- 이를 통해 사용자나 전문가가 모델이 제공한 정보를 추적하고 검증할 수 있습니다.
- 효율적인 지식 업데이트
- KG를 통해 지식을 동적으로 추가하거나 수정할 수 있어, LLM을 재학습하지 않고도 최신 정보를 반영할 수 있습니다.
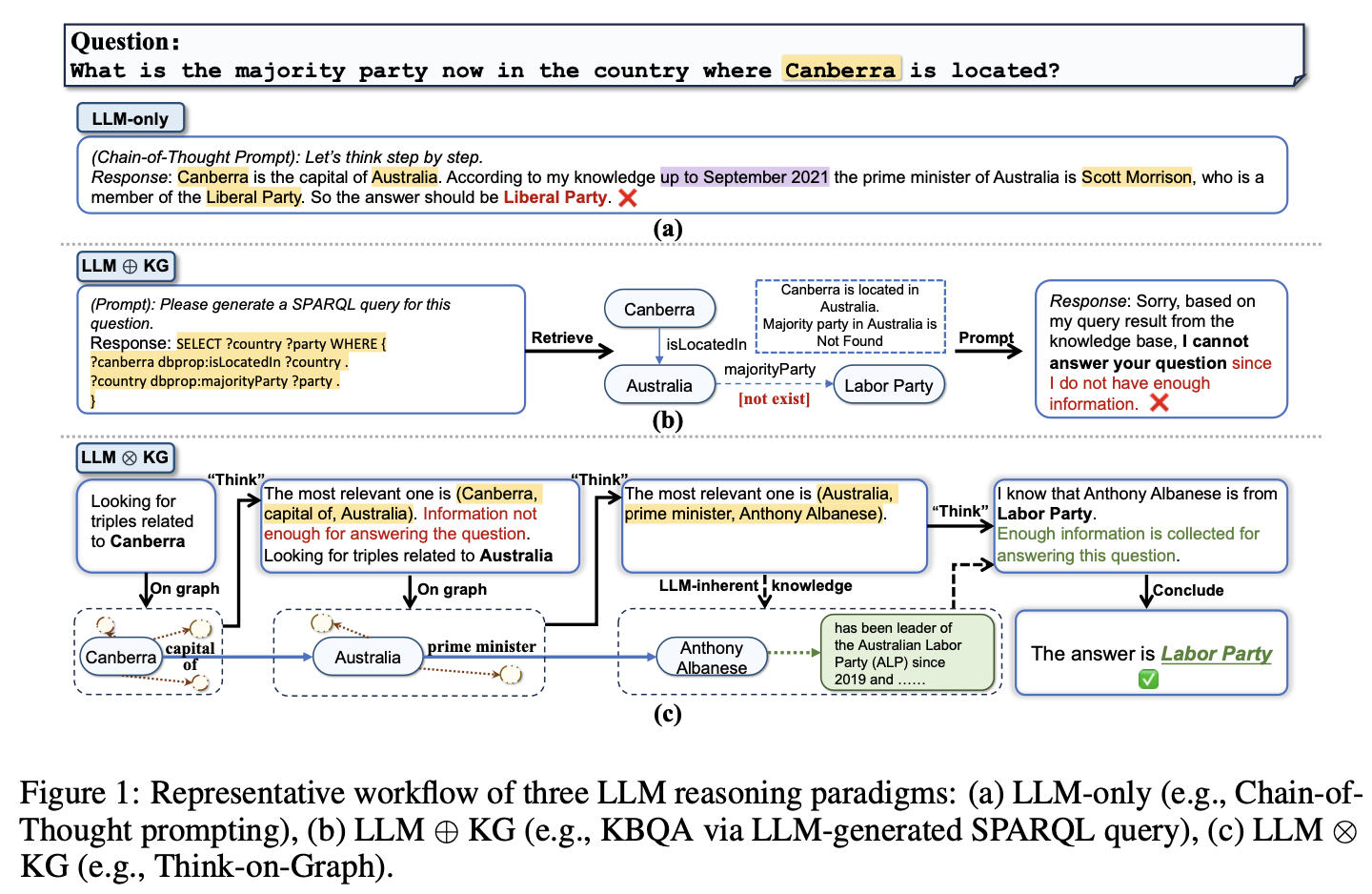
- (a) LLM 단독: CoT(Chain-of-Thought)를 사용해 LLM의 내재된 지식으로만 추론.
- (b) LLM⊕KG: SPARQL 쿼리를 통해 KG를 질의하지만, KG 데이터의 누락 시 실패 가능.
- (c) LLM⊗KG (ToG): LLM이 KG 탐색에 직접 참여하여 더 나은 추론 성능과 설명 가능성을 제공.
2. Methods
ToG(Think-on-Graph)는 "LLM⊗KG" 패러다임을 구현하기 위한 프레임워크로, LLM을 이용해 지식 그래프(KG)에서 빔 서치(Beam Search)를 수행하여 최적의 추론 경로를 탐색합니다.
ToG의 전체 프로세스 개요
ToG는 다음과 같은 절차로 작동합니다:
- 초기화 (Initialization): 질문에서 초기 토픽 엔티티를 식별하여 추론 경로의 시작점을 설정.
- 탐색 (Exploration): 빔 서치를 활용해 KG 내의 관계와 엔티티를 점진적으로 확장.
- 추론 (Reasoning): 현재 추론 경로의 충분성을 평가하고, 부족한 경우 탐색을 반복.
$P = \{p_1, p_2, \dots, p_N\}$
여기서, P는 상위 N개의 추론 경로를 의미하며, 각 반복(iteration)마다 업데이트됩니다.

1) 초기화 단계 (Initialization of Graph Search)
질문을 기반으로 LLM은 초기 토픽 엔티티를 식별하고, 탐색할 상위 N 개의 추론 경로를 생성합니다.
- 초기 토픽 엔티티 집합:
$E_0 = \{e_{01}, e_{02}, \dots, e_{0N}\}$
- 엔티티의 수는 질문의 내용에 따라 N보다 적을 수도 있음.
- LLM이 질문에서 주요 개체(예: 인물, 장소, 개념)를 자동으로 추출하여 KG에서 초기 탐색 시작점 제공.
2) 탐색 단계 (Exploration)
탐색 단계에서는 빔 서치를 사용하여 KG의 인접 관계와 엔티티를 반복적으로 확장합니다.
2-1) 관계 탐색 (Relation Exploration)
KG의 현재 엔티티에서 가장 관련성이 높은 관계(Relation)를 탐색하는 과정입니다.
- 검색(Search):
- 각 엔티티 enD−1와 연결된 관계를 추출.
- $R_{cand}^D = \{r_1, r_2, \dots, r_k\}$
- 예시: "Canberra"와 연결된 관계 → {capital of, country, territory}
- 가지치기(Prune):
- 질문과의 유사성을 평가하여 상위 N개 관계만 유지.
- $R^D = \text{Top-N}(R_{cand}^D)$
2-2) 엔티티 탐색 (Entity Exploration)
선택된 관계를 이용해 해당 관계에 연결된 **엔티티(Entity)**를 탐색합니다.
- 검색(Search):
- 새로운 관계에서 가능한 엔티티 검색.
- 예시: {Australia, Australian Capital Territory}
- 가지치기(Prune):
- 질문과의 관련도를 평가하고, 상위 엔티티를 선택.
3) 추론 단계 (Reasoning)
탐색을 통해 생성된 경로를 바탕으로 LLM은 현재 정보가 충분한지 평가합니다.
- 충분성 평가:
- 현재 추론 경로가 답변을 생성하기에 적절한지 판단.
- 충분한 경우, LLM이 최종 답을 생성.
- 부족할 경우, 탐색을 반복하거나 최대 탐색 깊이(Dmax) 도달 시 종료.
- 최대 반복 제한:
- ToG는 최대 2ND+D+1회의 LLM 호출을 필요로 하며, 제한에 도달하면 LLM의 내재된 지식만으로 답을 생성.
4) Relation Based ToG (ToG-R)
기존의 ToG와 달리, ToG-R은 추론 경로를 엔티티가 아닌 관계 체인 중심으로 구성하여 효율성을 극대화합니다.
- ToG-R의 특징:
- LLM 기반 엔티티 가지치기를 생략하여 계산 비용 절감.
- 관계 중심으로 탐색하여 중간 엔티티 정보 누락 문제를 완화.
ToG-R의 주요 단계
- 토픽 엔티티에서 관계 체인을 추출: $P = \{(e_0, r_1, r_2, \dots, r_D)\}$
- 무작위 엔티티 선택을 통해 검색 속도 향상.
ToG 대비 장점:
- LLM 호출 횟수 감소: 최대 ND+D+1회로 줄어듦.
- 관계 중심 탐색: 중간 엔티티가 명확하지 않은 경우에도 더 나은 성능 유지.
| 성능 | 더 정확한 추론 | 더 빠른 추론 |
| LLM 호출 횟수 | 2ND+D+1 | ND+D+1 |
| 주요 장점 | 설명 가능성, 정확성 | 비용 절감, 속도 개선 |
3. Experiments
1) 실험 설계
- 다중 홉 질의 응답(KBQA): CWQ, WebQSP, GrailQA, QALD10-en
- 단일 홉 질의 응답: Simple Questions
- 기타 태스크: 오픈 도메인 QA(WebQuestions), 슬롯 필링(T-REx, Zero-Shot RE), 사실 검증(Creak)
- 평가지표: 정확 매치(Hits@1) 사용.
- 사용한 LLM 모델: GPT-4, ChatGPT (GPT-3.5-turbo), LLaMA-2-70B
- 환경 : 8개의 A100 GPU로 실행
- 세부 설정:
- 빔 서치 너비(N) 및 깊이(Dmax)는 각각 3으로 설정.
- 최대 토큰 길이 256으로 제한.
- KG 소스:
- Freebase (CWQ, WebQSP, GrailQA, Simple Questions, WebQuestions)
- Wikidata (QALD10-en, T-REx, Zero-Shot RE, Creak)
- 모든 데이터셋에 대해 5-shot 프롬프트 사용.
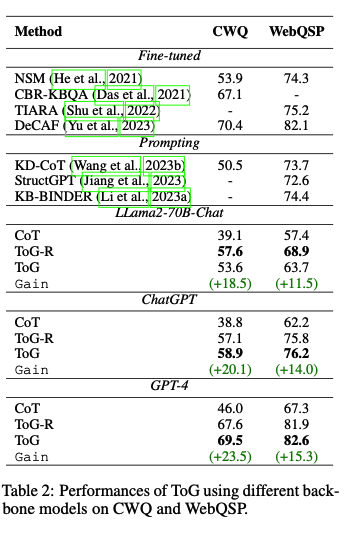
2) 주요 결과
- mutil-hop vs single-hop / different datasets
- ToG의 성능을 기존 방법들과 비교한 결과, 9개 데이터셋 중 6개에서 새로운 SOTA를 달성하였습니다.
- 우수한 성능 달성 데이터셋:
- WebQSP, GrailQA, QALD10-en, WebQuestions, Zero-Shot RE, Creak
- 경쟁력 있는 성능:
- CWQ에서는 기존 SOTA 대비 0.9% 낮았으나(CoT 69.5% vs ToG 70.4%), CoT 대비 유사한 성능 달성.
- ToG는 멀티홉 추론이 필요한 작업에서 탁월한 성능을 보이며, 이는 LLM의 심층 추론 능력을 크게 향상시킴을 입증.

- backbone 모델에 따른 비교
3) Ablation Study
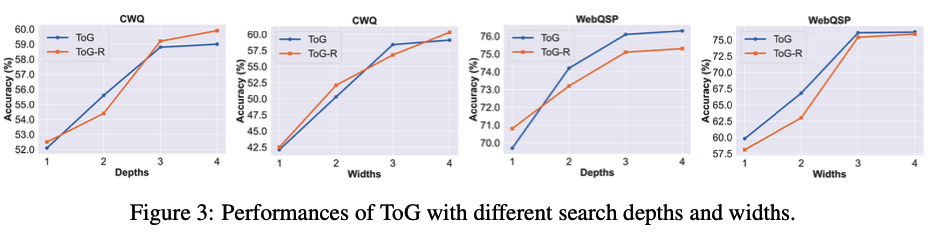
- Do search depth and width matter for ToG?
- 깊이와 너비가 증가할수록 성능이 향상되지만, 깊이 3 이후로는 성능 향상 둔화 및 비용 증가 발생.
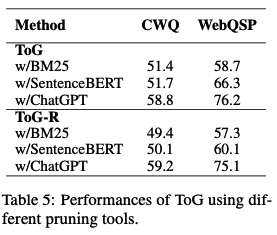
- Comparing the affects from different pruning tools.
- LLM이 pruning tool로써 성능이 제일 높음.
- How do different prompt designs affect ToG?

4) ToG의 지식 추적 및 수정 기능 (Knowledge Traceability and Correctability)
ToG는 모델의 추론 경로를 명확히 제공하며, 이를 통해 사용자가 추론 결과를 검증하고 수정할

수 있습니다.
- 질문: "What is mascot Phillie Phanatic’s team’s spring training stadium?"
- ToG의 초기 답변: "Bright House Field" (잘못된 응답).
- ToG는 추론 경로를 추적하여 문제의 원인이 오래된 KG 정보(“Spectrum Field” → “Bright House Field”)임을 발견.
- 사용자가 이 문제를 수정하고 이후 정확한 답을 얻을 수 있음.
ToG는 인과추론을 하는 효과적인 프레임워크입니다. 하지만, 이런 반복적인 function calling을 논리적 추론력을 가져오지만 연산 효율이 좋지는 않다고 생각합니다. GNN, 특히 타 논문들에서는 GAT를 많이 활용하는데 GNN 모델들을 통한 접근이 더 높은 추론력과 연산 효율을 가져다줄 것입니다.
그래서 다음은 GNN-LLM 이라는 논문에 대해 리뷰할 예정입니다.ㅎㅎ
'STUDY > Paper Review' 카테고리의 다른 글
| [Paper Review] Graphusion (0) | 2025.03.26 |
|---|---|
| [Paper Review] Think-on-Graph 2.0 (0) | 2025.03.02 |
| [Paper review] GraphRAG 논문 비교 (0) | 2025.02.22 |
| [Paper review] GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning (0) | 2025.02.03 |
| [Paper review] Don’t Do RAG:When Cache-Augmented Generation is All You Need for Knowledge Tasks (0) | 2025.01.08 |



