

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 마이온컴퍼니
- Join
- tog
- SQL
- DFS
- 파이썬
- GNN
- 멋재이사자처럼
- parklab
- 마이온
- 그리디
- folium
- likelion
- TiL
- kgc
- 멋사
- 멋쟁이사자처럼
- paper review
- graphrag
- seaborn
- intern10
- Python
- 프로젝트
- 인턴10
- likelionlikelion
- ux·ui디자인
- DP
- 알고리즘
- Rag
- 시각화
- Today
- Total
지금은마라톤중
[Paper Review] Think-on-Graph 2.0 본문
THINK-ON-GRAPH 2.0 :
DEEP AND FAITHFUL LARGE LANGUAGE MODEL REASONING WITH KNOWLEDGE-GUIDED RETRIEVAL AUGMENTED GENERATION
0. ABSTRACT
대형 언어 모델(LLMs)은 자연어 처리 분야에서 강력한 성능을 보이지만, 복잡한 질문을 처리할 때 지식 부족과 환각(hallucination) 문제를 겪습니다. 이를 보완하기 위해 RAG(Retrieval-Augmented Generation) 방식이 도입되었지만, 기존 방식은 깊이 있는 정보 검색이 어려워 복잡한 추론을 수행하는 데 한계가 있습니다.
ToG-2(Think-on-Graph 2.0)는 이러한 문제를 해결하기 위해 KG(지식 그래프)와 문서 검색을 긴밀히 결합한 새로운 하이브리드 RAG 프레임워크입니다. KG를 활용하여 문서 간 관계를 형성하고, 문서를 엔티티 맥락으로 활용하여 그래프 검색을 강화하며, 그래프 검색과 문맥 검색을 반복 수행(iterative retrieval)하여 LLM이 보다 신뢰성 있는 답변을 생성하도록 지원합니다.
1. Introduction
연구 배경 및 기존 RAG의 한계
- RAG(Retrieval-Augmented Generation)은 LLM(대형 언어 모델)의 지식 부족(knowledge deficiency)과 환각(hallucination) 문제를 해결하기 위한 접근법.
- 그러나 기존 RAG 방식들은 복잡한 추론(complex reasoning)이 필요한 경우 정보 검색의 깊이(depth)와 완전성(completeness)을 보장하지 못하는 한계가 있음.
- 이를 극복하기 위해 다양한 검색 최적화 기법이 연구되었으나(Kahneman, 2011; Yu et al., 2023; Edge et al., 2024), 여전히 인간과 같은 사고 경로(reasoning trajectory)를 유지하는 데 어려움이 있음.

기존 RAG 방식별 문제점
| 방식 | 장점 | 한계점 |
| 텍스트 기반 RAG (Text-based RAG) | - 문서 간 의미적 유사성(semantic similarity) 측정 가능 | - 구조적 관계(structural relationships) 파악 불가 - 다단계 추론(multi-step reasoning) 어려움 |
| KG 기반 RAG (KG-based RAG) | - 지식 간 관계를 구조적으로 표현 가능 - 해석 가능성(interpretability) 제공 |
- 지식 불완전성(knowledge incompleteness) 존재 - 최신 정보 반영 어려움 |
| 하이브리드 RAG (Hybrid RAG: KG + Text) | - 텍스트와 KG의 장점 결합 | - 단순 병합 수준에 머물러 검색 보완 효과 부족 - 깊이 있는 검색 수행 어려움 |
이러한 문제를 해결하기 위해 ToG-2(Think-on-Graph 2.0) 모델을 제안함.
ToG-2의 주요 기여점
| 기여점 | 설명 |
| 심층적 정보 검색 (In-Depth Retrieval) | - KG를 활용하여 문맥 검색(Context Retrieval) 정교화 - 문서를 노드 컨텍스트(node context)로 활용하여 검색 최적화 |
| 신뢰할 수 있는 추론 (Faithful Reasoning) | - KG와 문서 검색을 협력적인 검색(collaborative retrieval) 방식으로 수행하여 LLM이 신뢰할 수 있는 답변 생성 |
| 효율성 (Efficiency) 및 적용성 (Effectiveness) | - 훈련이 필요 없는 Training-Free 방식으로 다양한 LLM과 즉시 결합 가능 - KG 없이도 문서에서 엔티티를 추출해 자동 그래프화(graph construction) 가능 |
ToG-2는 7개 데이터셋 중 6개에서 SOTA 성능을 달성했으며, LLaMA-2-13B 같은 소형 모델도 GPT-3.5 수준으로 성능 향상이 가능함.
2. Related Works
기존 연구들은 RAG의 성능을 개선하기 위해 다양한 접근 방식을 제안했으나, 여전히 심층적인 추론을 위한 최적화가 부족
1. 텍스트 기반 RAG (Text-based RAG)
- 검색과 생성 과정의 반복(iterative retrieval-generation)을 통해 답변 품질을 향상.
- 대표 연구:
- ITER-RETGEN (Shao et al., 2023): 검색과 생성을 교대로 반복하는 방식
- Chain of Thought (CoT) 기반 RAG (Trivedi et al., 2023): CoT를 이용한 검색 가이드 기법
- 한계점:
- 문서 간 관계를 깊이 파악하기 어려움
- 검색이 반복될수록 연산량 증가 → 비효율적
- 검색 과정에서 오류가 누적될 가능성 존재
2. KG 기반 RAG (KG-based RAG)
- KG(지식 그래프)는 구조화된 지식 표현을 통해 추론 성능을 높이는 방식.
- 대표 연구:
- 초기 연구들은 LLM 내부에 KG를 임베딩하는 방식을 연구 (Sun et al., 2020; Peters et al., 2019).
- 최근 연구들은 LLM과 KG를 외부적으로 결합하여 활용 (Jiang et al., 2024; Sun et al., 2024).
- 한계점:
- 지식 불완전성(knowledge incompleteness) 문제 존재 → 최신 정보 반영 어려움
- KG에 포함되지 않은 정보는 검색 불가능
3. 하이브리드 RAG (Hybrid RAG)
- KG와 텍스트 데이터를 결합하여 보다 강력한 검색 성능을 목표로 함.
- 대표 연구:
- Chain-of-Knowledge (CoK, Li et al., 2024c): Wikipedia, Wikidata, Wikitable을 결합한 RAG
- GraphRAG (Edge et al., 2024): 문서에서 KG를 자동 생성하여 RAG 성능 강화
- HybridRAG (Sarmah et al., 2024): 벡터 DB와 KG를 결합하여 추론 능력 개선
- 한계점:
- 대부분의 연구가 KG와 텍스트 데이터를 단순히 병합(aggregation)하는 수준
- KG 검색을 문서 검색에 반영하거나, 문서 검색 결과로 KG 검색을 보정하는 방식 부족
3. Methodology
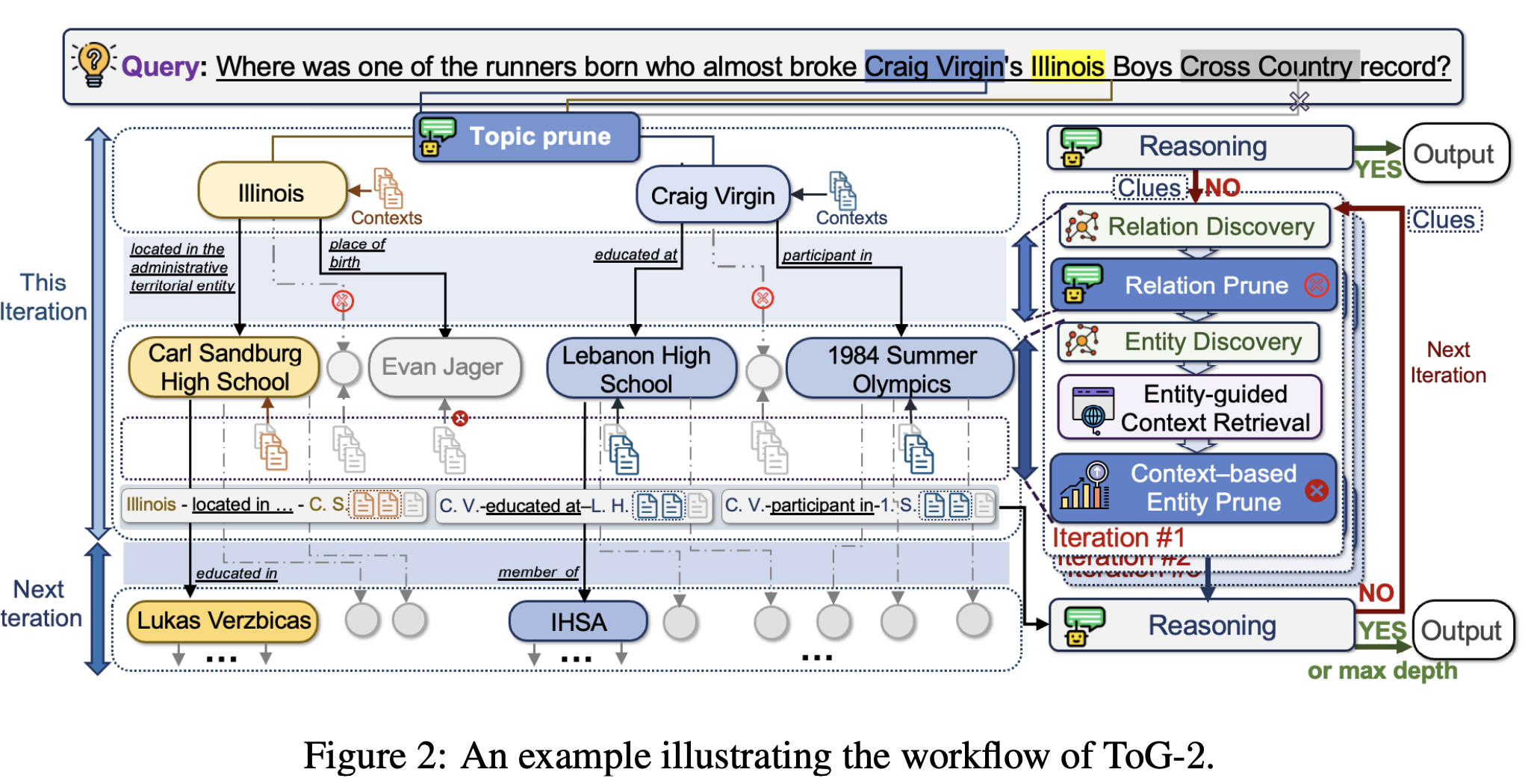
- 핵심 프로세스:
- 질문에서 핵심 엔티티 추출 (Entity Extraction)
- 그래프 탐색 (Graph Retrieval)
- 문서 검색 (Context Retrieval)
- LLM 기반 추론 및 반복적 검색 (Iterative Reasoning & Retrieval)
- 이러한 과정을 반복하면서 KG와 문서 검색을 상호 보완적으로 수행하는 Tight-Coupling Hybrid RAG를 구현.
3.1 초기화 (Initialization)
- 질문에서 핵심 엔티티(topic entities) 추출
- 주어진 질문 q에서 등장하는 엔티티를 KG와 연결(Entity Linking).
- LLM 또는 Entity Linking(EL) API를 사용하여 엔티티 매칭 수행.
- Topic Prune (TP) 단계: 검색 출발점이 되는 중요한 엔티티를 선별.
- 초기 문서 검색
- Dense Retrieval Models (DRMs, 예: dual-tower & single-tower 모델)을 사용하여 해당 엔티티와 관련된 문서에서 상위 k개의 문맥 조각(chunks) 검색.
- LLM이 이 정보만으로 답변 가능하면 추가 검색을 수행하지 않음.
3.2 하이브리드 지식 탐색 (Hybrid Knowledge Exploration)
- ToG-2는 이 과정을 반복적으로 수행하여 KG 검색과 문서 검색을 서로 보완적으로 결합.
3.2.1 KG 기반 검색 (Knowledge-Guided Graph Search)
- 관계 탐색 (Relation Discovery)
- KG에서 현재 탐색 중인 엔티티 eji와 관련된 관계 Edge(eji)를 검색.
- 예제:
- Craig Virgin → place of birth → Illinois (연관성이 낮다면 이후 단계에서 제거됨).
- 관계 필터링 (Relation Prune, RP)
- LLM이 검색된 관계를 평가하여 문맥 정보를 포함할 가능성이 높은 관계만 선별.
- 두 가지 방법:
- 개별 관계 평가
- $PROMPTRP(e_j^i, q, Edge(e_j^i))$→ 정확하지만 비효율적.
- 전체 관계 평가
- $PROMPT_{RP cmb}(E_{topic}^i, q, \{Edge(e_j^i)\})$→ 속도 향상 가능.
- 낮은 점수를 받은 관계는 제거됨.
- 엔티티 탐색 (Entity Discovery)
- 필터링된 관계를 기반으로 새로운 연결 엔티티 $c_{j,m}^i$를 탐색.
- 예제:
- Craig Virgin → trained with → Evan Jager (새로운 엔티티 발견)
- 이후 문맥 검색(Context Retrieval)을 활용하여 유효한 엔티티를 선택.
3.2.2 문맥 기반 검색 (Knowledge-Guided Context Retrieval)
- 문서 검색을 통한 정보 강화
- 새로운 후보 엔티티를 바탕으로 관련 문서를 검색하여 컨텍스트 풀(Context Pool) 구성.
- 예제:
- Evan Jager 관련 문서에서 추가적인 문맥 정보를 수집.
- 엔티티 기반 문맥 검색 (Entity-Guided Context Retrieval)
- 문서 내 각 문맥 조각(chunk)의 유사도를 평가하여 가장 관련성이 높은 문맥을 선택.
- 검색 공식:
- $P_{c_{j,m}^i}$: 현재 엔티티와 관계를 포함하는 삼중항(triple).
- 검색된 문맥과 질문을 함께 평가하여 가장 관련성이 높은 문맥을 선별.
- 기존 ToG에서는 엔티티만의 유사도를 평가했지만, triple의 문장을 평가함으로써 의미적/구조적 특성 반영
- $s_{j,m,z}^i = DRM(q, [\text{triple sentence}(P_{c_{j,m}^i}) : \text{chunk}_{j,m,z}^i])$
- 문맥 기반 엔티티 필터링 (Context-Based Entity Prune)
- 검색된 문맥을 바탕으로 엔티티 중요도를 재평가하여 최적의 탐색 대상을 선정.
- 점수 계산:
- 가중치 $w_k = e^{-\alpha k}$ 적용 → 상위 검색 결과일수록 높은 가중치를 부여.
- ${score}(c_{j,m}^i) = \sum_{k=1}^{K} s_k \cdot w_k \cdot I(\text{k-th ranked chunk is from } c_{j,m}^i)$
- 상위 W개 엔티티를 다음 검색 대상으로 선정, 나머지는 제거됨.
3.3 LLM 기반 추론 (Reasoning with Hybrid Knowledge)
- LLM이 검색된 정보 평가
- LLM은 이전 검색에서 수집된 정보($Clues^{i-1}$, Triple Paths, Context Chunks)를 기반으로 질문에 답변할 수 있는지 평가.
- 만약 충분한 정보가 있다면 즉시 답변을 생성.
- 추가 검색 필요 시 질의 재구성
- 만약 정보가 충분하지 않다면, LLM이 다음 검색을 위한 단서($Clues^{i}$)를 생성.
- 이 새로운 단서를 바탕으로 질의를 재구성(Query Reformulation)하고 추가 검색 수행.
- 이 과정은 최대 깊이(Depth D)까지 반복됨.
4. Experiments
4.1 데이터셋 및 평가 지표 (Datasets and Metrics)
데이터셋
- 다중 홉(Multi-hop) KBQA (Knowledge Base Question Answering) 데이터셋
- WebQSP (Yih et al., 2016)
- QALD10-en (Usbeck et al., 2023)
- 다중 홉 복잡한 문서 QA 데이터셋
- AdvHotpotQA (Ye & Durrett, 2022)
- HotpotQA의 하위 집합으로, 다중 문서를 이용한 복잡한 추론이 필요함.
- AdvHotpotQA (Ye & Durrett, 2022)
- 슬롯 필링(Slot Filling) 데이터셋
- Zero-Shot RE (Petroni et al., 2021)
- 사실 검증(Fact Verification) 데이터셋
- FEVER (Thorne et al., 2018)
- Creak (Onoe et al., 2021)
평가 지표
- Fact Verification(FEVER, Creak) → Accuracy (정확도)
- 나머지 QA 데이터셋 → Exact Match (EM)
- Recall과 F1 점수는 사용되지 않음
- 이유: 지식 소스가 문서에 한정되지 않기 때문.
- Recall과 F1 점수는 사용되지 않음
ToG-FinQA 데이터셋 (도메인 특정 QA 데이터셋)
- 일반 LLM의 사전 학습(pre-training)에 포함되지 않은 데이터셋을 활용하여 보다 엄격한 평가 수행.
- 2023년 중국 금융 보고서(financial statements)를 기반으로 KG를 구축하고, 97개의 다중 홉 질의 생성.
- KG에서 기업 및 조직을 엔티티로 추출하고, 7가지 관계 유형을 정의:
- 자회사(subsidiary), 주요 사업(main business), 공급업체(supplier), 형제 회사(sibling company), 대량 거래(bulk transaction), 고객(customer).
4.2 구현 세부 사항 (Implementation Details)
- GPT-3.5-turbo를 기본 백본(Backbone) LLM으로 설정하여 모든 방법을 동일 환경에서 비교.
- 추가 실험: GPT-4o, LLaMA3-8B, Qwen2-7B에서도 성능 비교 수행.
검색 설정
- 탐색 너비(width, W) = 3
- 최대 반복 횟수(depth, D) = 3
- 관계 필터링(Relation Prune) 시 Relevance Score 임계값 = 0.2.
문서 검색 및 엔티티 정제
- BGE-embedding 모델 사용 (추가 미세 조정 없음).
- 상위 10개 문장(K=10)을 선택하여 엔티티 점수 계산.
4.3 주요 실험 결과 (Main Results)
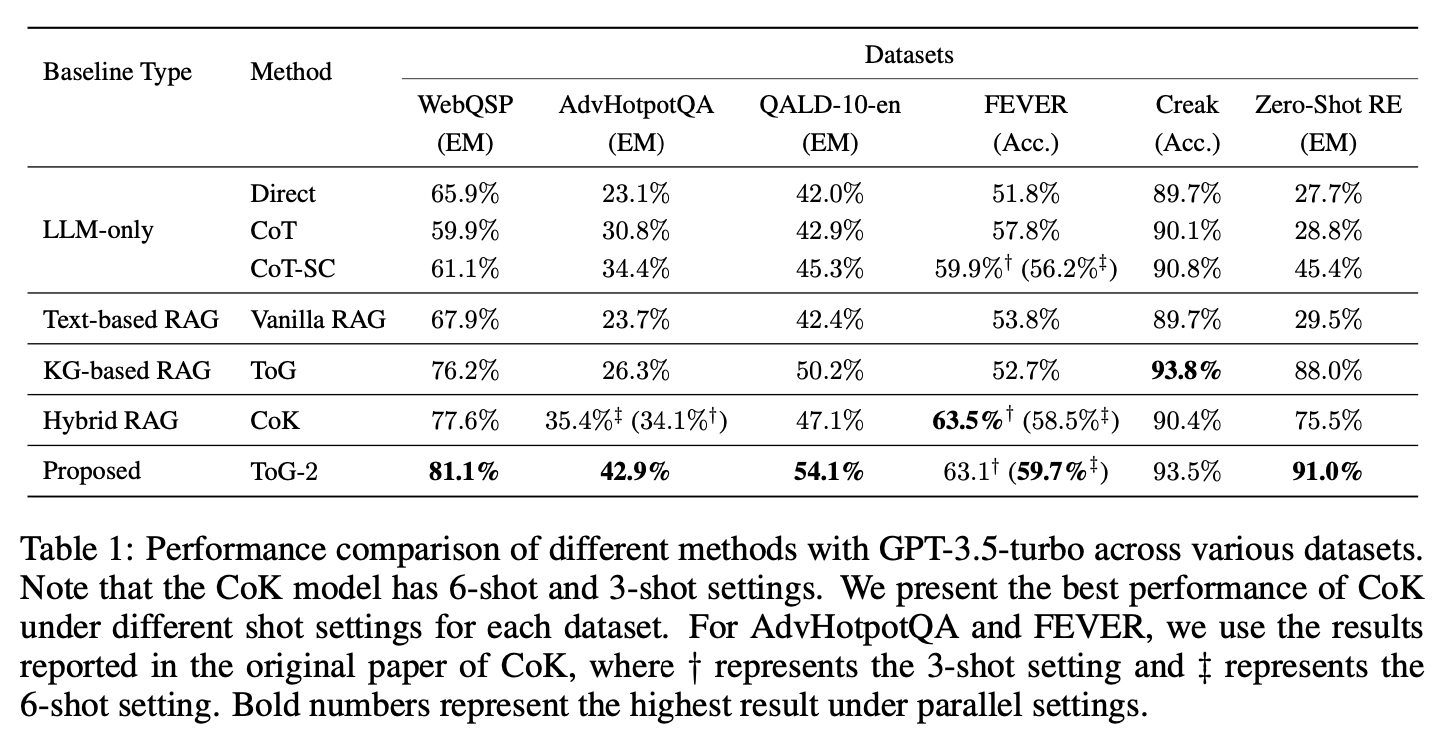
- ToG-2는 대부분의 데이터셋에서 기존 방법들을 능가함.
- AdvHotpotQA에서 ToG-2는 기존 ToG보다 16.6% 향상 → 다중 홉 추론에 강점이 있음을 보여줌.
- FEVER와 Creak에서는 KG 기반 RAG(ToG)와 유사한 성능 → 단일 홉 추론에서는 큰 차이가 없음.

- 기존 RAG 및 CoT 기반 방법들은 전혀 성능을 내지 못함(0%).
- ToG-2는 34.0%의 성능을 기록하며 도메인 특정 질의에서 강력한 성능을 보임.
4.4 Ablation Study
4.4.1 LLM 백본(Ablation of LLM Backbones)
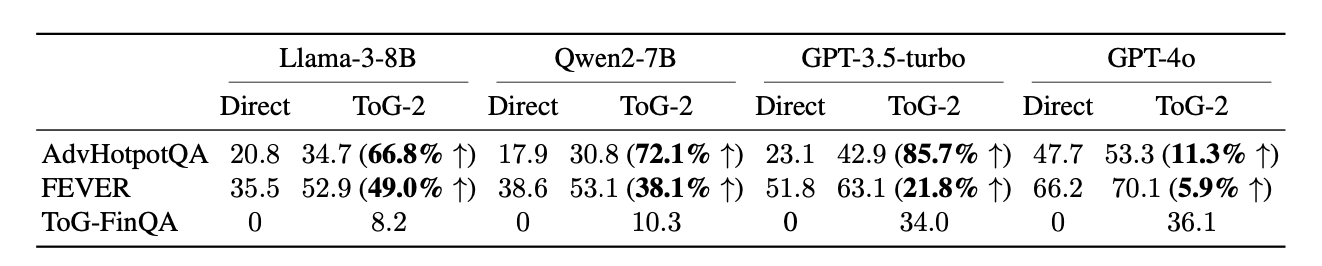
- 성능이 낮은 LLM일수록 ToG-2의 성능 향상 효과가 큼.
- Llama-3-8B, Qwen2-7B는 각각 66.8%, 72.1% 성능 향상.
- 이는 ToG-2가 지식 검색을 통해 저성능 LLM의 지식 및 이해력 부족을 보완하는 역할을 한다는 것을 의미.
- 고성능 LLM에서도 성능 향상
- GPT-4o도 ToG-2를 사용하면 성능이 향상됨(5.9%~11.3%).
- 하지만 상대적으로 적은 개선폭 → GPT-4o는 사전 학습에서 이미 많은 지식을 내장하고 있음.
4.4.2 엔티티 필터링(Entity-Pruning Tools) 비교
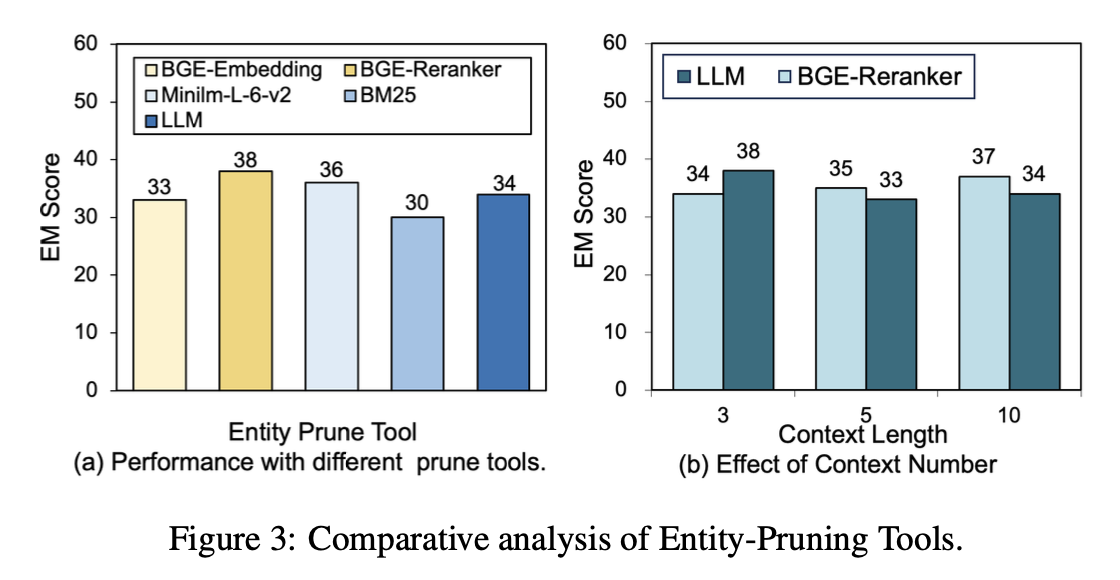
- BGE-Reranker가 가장 높은 성능을 기록하며, Minilm이 그 뒤를 이음.
- BM25는 낮은 성능을 보였지만 빠른 속도를 제공 → 일부 효율성이 중요한 환경에서는 유용할 수 있음.
- LLM을 사용한 필터링은 정확성이 떨어지고 실행 속도가 느림 → ToG-2에서는 사용하지 않음.
5. Conclusion
- ToG-2는 기존 RAG의 한계를 극복하기 위해 KG×Text RAG 패러다임을 도입.
- KG 기반 검색과 문서 기반 검색을 상호 보완적으로 수행하여 신뢰할 수 있는 정보 검색을 가능하게 함.
- 기존 RAG 및 LLM 단독 방법보다 뛰어난 성능을 보이며, 특히 도메인 특정 QA에서 큰 효과를 보임.
- 추가 훈련이 필요 없으며, 다양한 LLM에서 즉시 적용 가능.
ToG-2는 기존 ToG의 방법론을 개선한 연구입니다. 기존 ToG 논문에서는 LLM에 의존적이며 cost가 많이 든다는 한계점이 있었습니다. 해당 논문에서는 기존의 프레임워크 위에서 검색과 프루닝, 그리고 Clues를 통한 추론 향상까지 개선된 것을 확인할 수 있었습니다. 검색단계에서 DRM 모델을 활용하고 가중치를 활용한 프루닝을 통해 의미적/구조적 평가를 통해 검색함으로써 LLM에 대한 의존력을 낮췄습니다. 또한 Clues라는 피드백 시스템을 도입하였는데 AGENT-G 논문에서도 Critics Module 을 통해 비슷한 역할을 부여한 것을 성능 향상의 결과를 언급한 바 있습니다. LLM을 활용한 GraphRAG는 SOTA의 성능을 보여주고 있어 LLM의 활용은 불가항력입니다. 그렇기에 그 안에서 LLM의 성능을 잘 활용할 수 있도록하는 연구가 또다른 SOTA를 만들 것이라 생각합니다.
'STUDY > Paper Review' 카테고리의 다른 글
| [Paper Review] Retrieval-Augmented Generation with Hierarchical Knowledge (3) | 2025.04.08 |
|---|---|
| [Paper Review] Graphusion (0) | 2025.03.26 |
| [Paper review] GraphRAG 논문 비교 (0) | 2025.02.22 |
| [Paper review] GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning (0) | 2025.02.03 |
| [Paper review] THINK-ON-GRAPH: DEEP AND RESPONSIBLE REASONING OF LARGE LANGUAGE MODEL ON KNOWLEDGE GRAPH (0) | 2025.01.21 |



