
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 알고리즘
- seaborn
- 멋재이사자처럼
- DP
- kgc
- 그리디
- TiL
- 인턴10
- tog
- graphrag
- 멋쟁이사자처럼
- Python
- Rag
- likelionlikelion
- SQL
- 마이온컴퍼니
- likelion
- 프로젝트
- 파이썬
- 시각화
- Join
- intern10
- 마이온
- ux·ui디자인
- DFS
- parklab
- folium
- GNN
- paper review
- 멋사
- Today
- Total
지금은마라톤중
[Paper Review] How to Mitigate Information Loss in Knowledge Graphs for GraphRAG 본문
[Paper Review] How to Mitigate Information Loss in Knowledge Graphs for GraphRAG
Ojungii 2025. 5. 20. 14:40How to Mitigate Information Loss in Knowledge Graphs for GraphRAG
: Leveraging Triple Context Restoration and Query-Driven Feedback
0. Abstract
최근 KG를 활용하는 LLM 연구들은 KG가 완전하다는 가정을 하고 있어, KGC의 본절적 한계와 비정형 글을 엔티티-엣지의 트리플로 바꾸면서 문맥적 손실을 가져옵니다.
해당 논문에서는 Triple Context Restoration and Query-driven Feedback(TCR-QF) 프레임워크를 제안합니다.
문맥 정보를 재구성하고 반복적인 쿼리 기반 피드백으로 KG 구조를 정제합니다.
1. Introduction
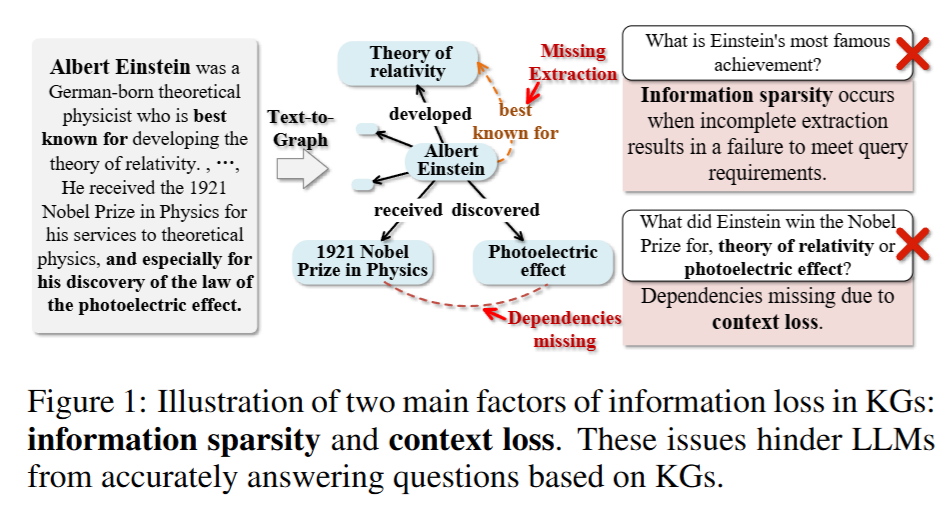
- 문제 제기: 기존 KG-augmented LLM 방식은 Knowledge Graph(KG)의 완전성(completeness)을 전제로 하지만, 실제로는 KG 구축 과정에서 정보 희소성(sparsity)과 문맥 손실(context loss) 문제가 존재함.
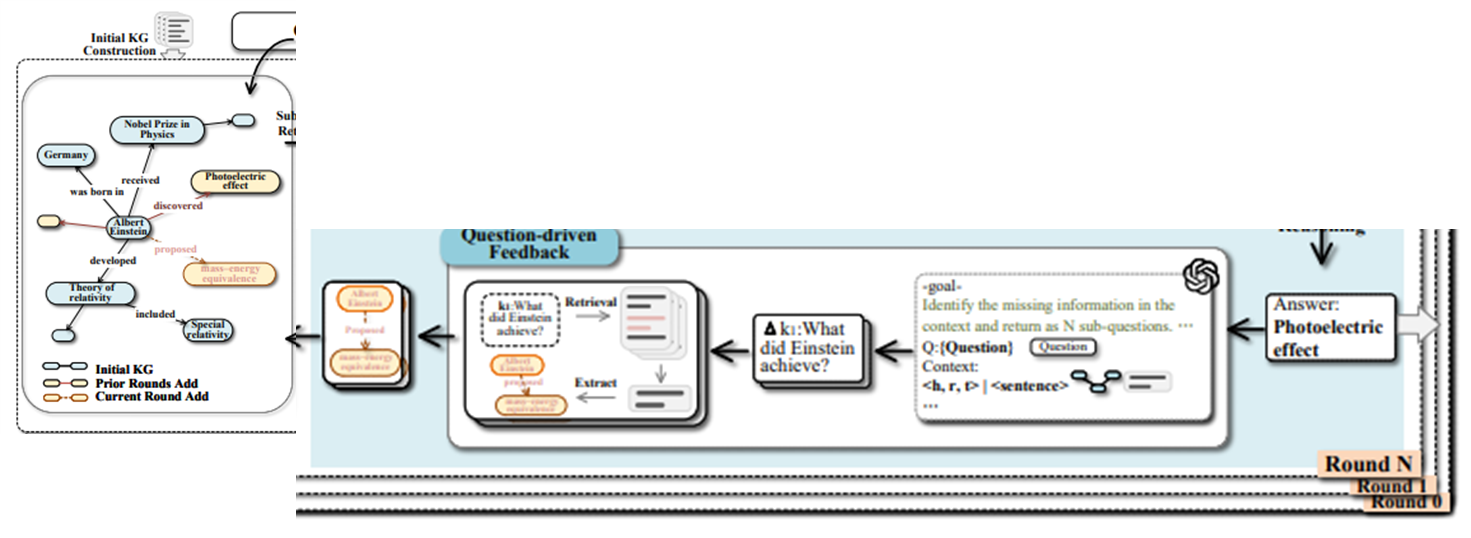
- 예시: Einstein에 대한 정보에서 'photoelectric effect'는 수상 이유이지만, 삼중항으로 표현되면 그 이유가 사라짐.
- 제안 방법 : TCR-QF Framework
- Triple Context Restoration: 삼중항에 대응되는 원문 문장을 추출해 문맥 회복.
- Query-Driven Feedback: 질의 과정에서 부족한 정보를 보완하여 KG를 동적으로 갱신.
- 기여점 요약:
- KG–LLM 통합의 핵심 문제 분석 (문맥 손실, 정보 누락)
- TCR-QF 프레임워크 제안
- 5개 QA 데이터셋에서 EM 29.1%, F1 15.5% 개선
2. Related Work
- 기존 GraphRAG의 문제점 요약:
- KG가 불완전할 경우 LLM 성능 저하
- 정적 KG 사용 → 정보 손실 회복 불가
- 최근 방법론:
- 서브그래프 검색 최적화
- LLM을 이용한 KG 자동 생성
- KG+텍스트 혼합 기반 하이브리드 RAG
- 한계: 문맥 없는 triple만으로는 reasoning이 제한적임.
3. Proposed Method
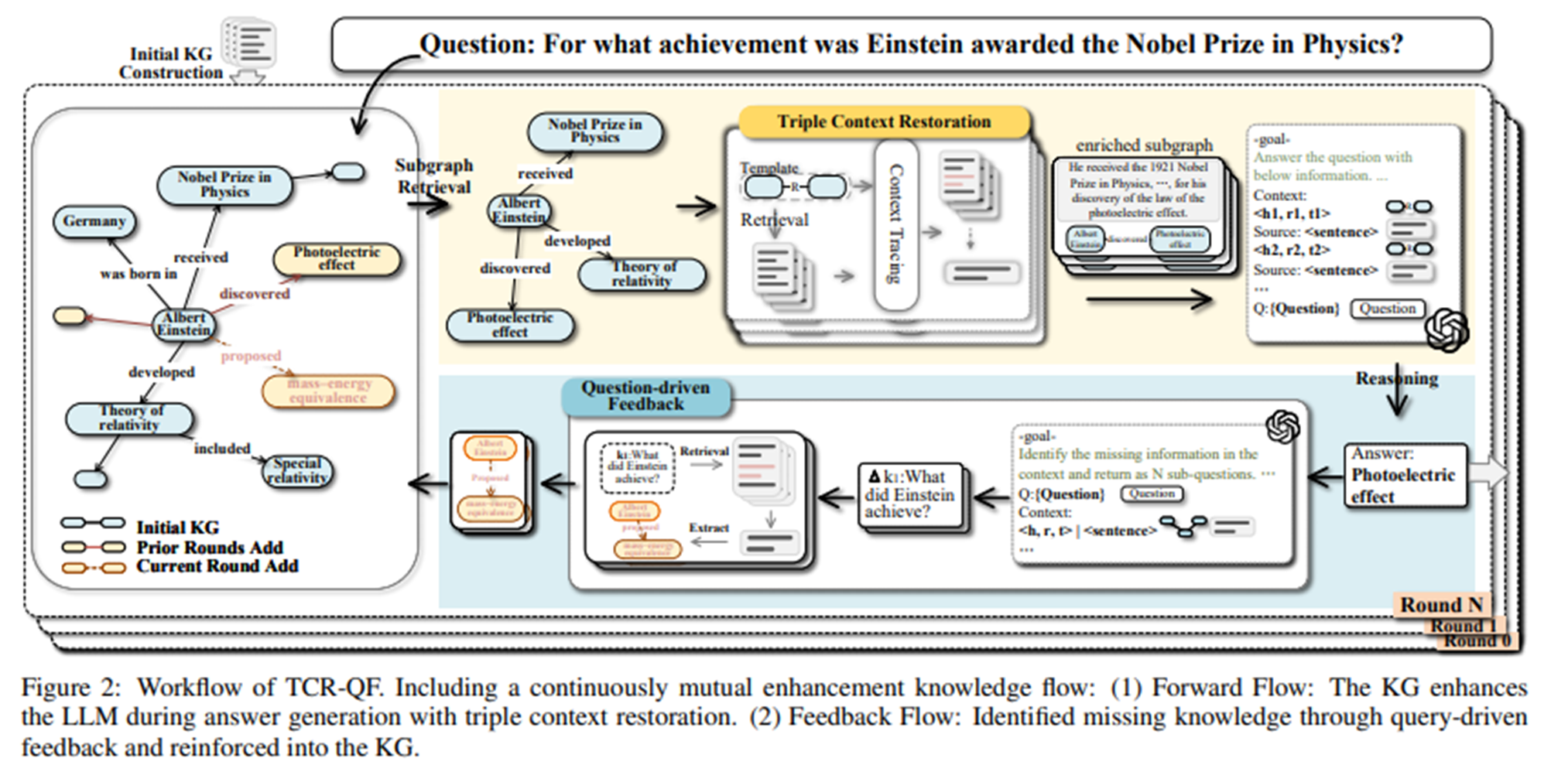

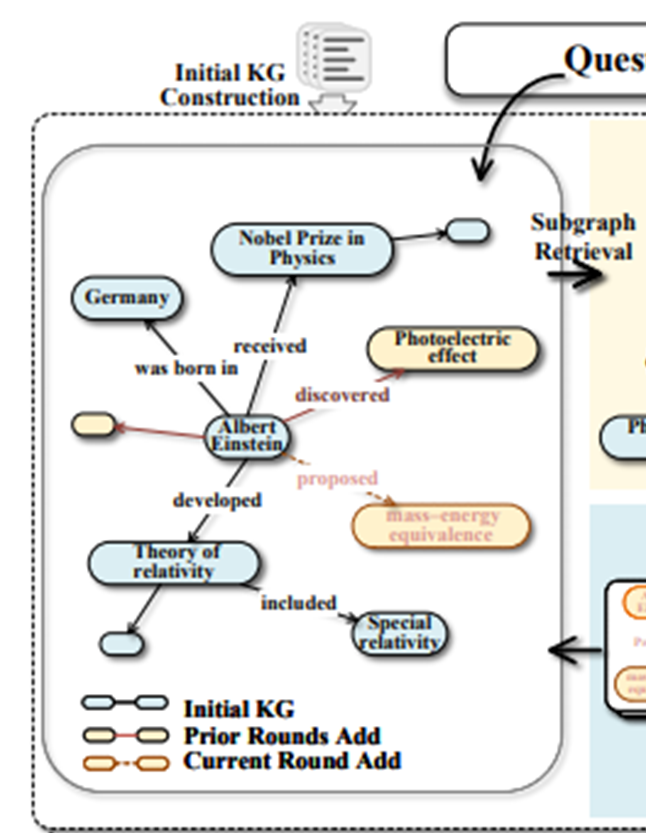
3.1 Knowledge Graph Construction
- 텍스트 → KG 변환:
- 문서 분할 (MAX_LEN=2048, OVERLAP=256)
- LLM을 통해 triple 추출 및 엔티티 타입/설명 포함
3.2 Subgraph Retrieval
-
쿼리와 관련된 서브그래프 추출
-
LLM 기반의 beam search와 pruning으로 검색
(Think-on-graph) 방식 사용

3.3 Triple Context Restoration
-
템플릿 생성 : 트리플을 자연어로 → “e_h r e_t”.
-
임베딩 모델을 활용해 임베딩 후 템플릿과 원문의 유사도 판단.
-
가장 유사한 문장을 트리플에 연결

3.4 Iterative Reasoning with Query-Driven Feedback

-
쿼리에 대해 초기 답변 생성 후 아래 과정 반복
-
Missing Knowledge Identification
-
LLM으로 손질 정보 있는지 파악 후 있다면 ∆K^((i))에 sub-question으로 표현
-
-
-
Knowledge Graph Enrichment
-
Sub-question과 원문에 대해 dense retriever 수행
-
관련 트리플 추출
-
중복을 확인하고 KG에 업데이트
-
-
Iterative Reasoning and Update
-
∆K^((i))가 없으면 종료
-
최대 iteration = 20
4. Experiments
- 데이터셋
- 5개 QA benchmark: 2WikiMultiHopQA, HotpotQA, ConcurrentQA, MuSiQue-Ans, MuSiQue-Full
- 비교군
- LLM Only (GPT-4o, CoT 등)
- Text-based RAG (LangChainQ&A)
- Graph-based RAG (ToG)
- Hybrid RAG (GraphRAG)
- Proposed: TCR-QF
- 성능 지표
- Exact Match (EM)
- F1 Score
4.1 Main Result
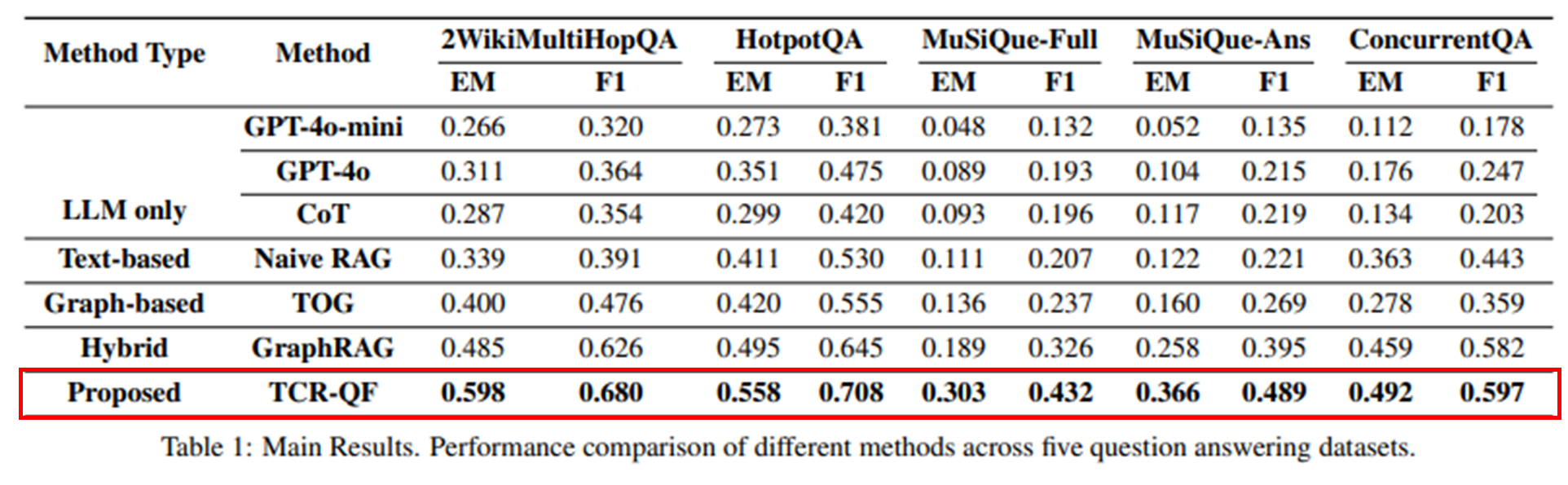
- TCR-QF가 가장 성능 좋음
4.2 Ablation Study
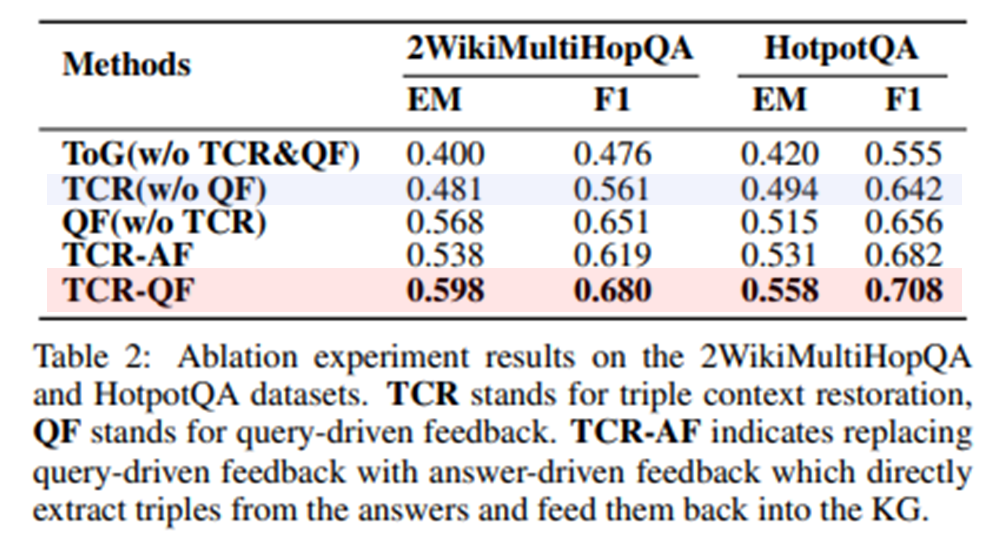
모듈별 영향력 평가
- QF가 가장 영향력 큼
- TCR-AF
- 답변 기반보다 쿼리 기반이 나음
- 에러의 전파나 불완전한 추론을 막기 때문
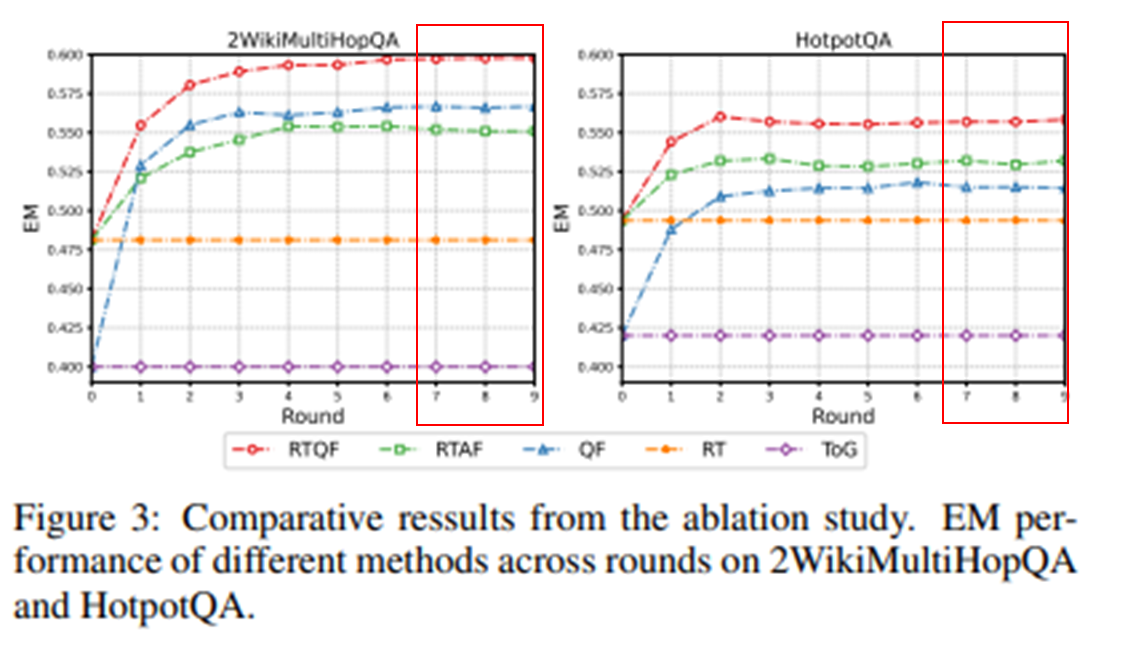
라운드별 성능 누적 비교
- 초반의 성능 향상이 큼
- 라운드가 지날수록 성능 수렴
- 7~8 라운드부터 고정
라운드별 경향성 추이
- KG가 점진적으로 보완됨에 따라 LLM의 추론 정확도도 같이 향상됨.
- 즉, KG 품질이 reasoning 성능에 직접적인 영향을 줌.
- TCR-QF는 초반 라운드에서 효과적으로 KG를 보완
- 8~10라운드: 성능 및 KG 구조 모두 거의 변화 없음

Insight
해당 논문의 방법론과 비슷하게 피드백을 통해 개선하는 선형 연구들이 있습니다. ToG-2에서는 피드백을 통해 쿼리를 재가공하지만 불완전한 그래프 내에서 검색한다는 점에서 여전히 한계가 존재했습니다. TCR-QF는 피드백을 통해 그래프 자체를 보완함으로써 동적인 보완이 가능하다고 할 수 있습니다. 근본적인 문제였던 그래프의 완전성을 해결함으로써 그래프를 통한 보다 심층적이고 유연한 추론이 가능해질 것이라 기대합니다.
장점도 있지만 실험의 약점도 존재합니다. 우선, 효율성 실험이 없습니다. 라운드별로 추가되는 트리플으 수가 다르기 때문에 토큰과 시간 소요 등의 효율성 체크를 통해 최적의 라운드 설계가 필요해보입니다. 또한 어떤 유사도 함수를 사용했는지 정확히 언급되어있지 않습니다. github 코드를 살펴보아도 나와있지 않는 것 같습니다.
TCR-QF를 통해 KGC 관련 연구에서 단순히 그래프 구축하는 것이 아닌 기존 문서의 불완전성을 보완하며 그래프 구축하는 방안에 대해서 시야를 확장했습니다.
'STUDY > Paper Review' 카테고리의 다른 글
| [Paper Review] Can LLMs be Good Graph Judger for KnowledgeGraph Construction? (2) | 2025.05.07 |
|---|---|
| [Paper Review] Retrieval-Augmented Generation with Hierarchical Knowledge (3) | 2025.04.08 |
| [Paper Review] Graphusion (0) | 2025.03.26 |
| [Paper Review] Think-on-Graph 2.0 (0) | 2025.03.02 |
| [Paper review] GraphRAG 논문 비교 (0) | 2025.02.22 |



