
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 그리디
- graphrag
- 마이온
- SQL
- 파이썬
- likelion
- paper review
- 알고리즘
- parklab
- Join
- 프로젝트
- 인턴10
- 멋재이사자처럼
- 멋쟁이사자처럼
- DFS
- folium
- ux·ui디자인
- likelionlikelion
- 마이온컴퍼니
- Python
- tog
- 멋사
- GNN
- kgc
- intern10
- DP
- TiL
- seaborn
- Rag
- 시각화
- Today
- Total
지금은마라톤중
멋사 AI스쿨 TIL - (19) 본문
2023.03.08
[지도학습]
지도 학습(supervised learning)은 훈련 데이터(Training Data)로부터 하나의 함수를 유추해내기 위한 기계 학습(Machine Learning)의 한 방법이다.
훈련 데이터는 '문제'에 해당되는 데이터(X_train)와 레이블이라고 부르는 '정답'이 적혀있는 데이터(y_train)로 구성되어 있습니다

- 사이킷런을 제외한 다른 라이브러리(XGBoost, LightGBM, CatBoost, TensorFlow, Keras 등)에서도 사이킷런 스타일의 API 를 제공하기도 한다.
● 지도학습 흐름
기출문제를 한번 풀어본다 -> X_train으로 학습!
풀어본 기출문제의 정답을 보고 채점해보자 !! -> y_train 으로 정답을 채점한다 !
실제 모의고사에서 시험을 쳐본다! -> X_test로 모델의 실력을 점검한다.
실제 모의고사의 정답을 확인한다! (모델 학습의 목표) -> 모델의 성적 y_test (예측해야할 Label값) 를 확인한다!
● 데이터분석 결측치 처리 방법
결측치를 채울 때 평균, 중앙값 등으로 채우기도 합니다. 결측치가 너무 많은데 해당 변수가 중요한 값일 때는 제거하는 것보다 채우는 것이 더 나을 수도로 있습니다. 상황에 따라 어떻게 채우느냐에 따라 성능이 나아질 수도 있고 나빠질 수도 있습니다.
(chat GPT 답변)
머신러닝에서 결측치를 채우는 방법은 여러 가지가 있습니다. 일반적으로는 다음과 같은 방법들이 사용됩니다.
평균값, 중앙값, 최빈값 등의 대푯값 사용: 해당 열의 결측치를 해당 열의 평균값, 중앙값, 최빈값 등으로 채웁니다.
예측 모델 사용: 해당 열의 값이 결측치인 행을 제외한 나머지 데이터를 이용하여 예측 모델을 만들고, 이를 사용하여 결측치를 채웁니다. 대표적으로 회귀 모델이나 K-NN 모델을 사용할 수 있습니다.
시계열 데이터에서의 선형보간, 보간법 등: 시계열 데이터의 경우, 이전 시점의 데이터를 이용하여 결측치를 보간하는 방법 등을 사용할 수 있습니다.
결측치 제거: 결측치가 너무 많거나 결측치를 채우는 것이 데이터의 품질을 떨어뜨린다고 판단될 경우, 해당 행 또는 열을 제거하는 방법을 사용할 수 있습니다.
이외에도 데이터의 특성에 따라 다양한 방법들이 있습니다. 따라서, 결측치를 채우는 방법은 데이터의 특성에 따라 선택되어야 합니다.
* 머신러닝에서 변수를 최대한 많이 사용한다고 꼭 좋은 성능을 내지는 않습니다. => Garbage In Garbage Out
● 학습과 예측 데이터 나누기
학습, 예측 데이터셋을 나눌 때는 직접 판다스로 나눠줄 수도 있고 scikit-learn 의 train_test_spilit 을 사용할 수도 있습니다. scikit-learn 의 전처리 기능은 다른 딥러닝 라이브러리에서도 함께 많이 사용하는 편입니다.
학습, 예측 데이터셋을 나눌 때는 5:5, 8:2, 7:3 등으로 나눌수도 있지만 학습데이터를 더 많이 나누는게 좋습니다. 공부를 더 많이 하고 시험을 봐야지 시험을 더 잘 볼 수있기 때문입니다.
| 질문🙋🏻♂️: 섞어서 나누었을 때 장점이 무엇인가요 ?
클래스가 여러 개 일 경우에 클래스의 수가 train, test에 균일하게 나뉘지 않을 수도 있습니다. train_test_split() 등의 기능을 사용하면 label값을 균형있게 나눠줄 수도 있습니다. 예를 들어 이탈여부를 예측하는데 이탈한다 안한다가 7:3 정도로 train에 있다면 test 에도 7:3 으로 들어있어야 제대로 학습하고 예측할 수 있습니다. 임의로 순서대로 나눴다면 train 에는 8:2 로 들어있는데 test 에는 6:4 로 들어있다면 예측의 성능이 떨어질 수도 있습니다.
=> 같은 비율로 만들어 줄 때 언더샘플링, 오버샘플링(KNN, smote) 등의 방법을 사용합니다
섞어서 나누면 안 되는 데이터도 있습니다. 어떤 데이터 일까요?
순서가 있는 데이터, 시계열 데이터는 섞어서 나누지 않고 순서대로 나눕니다
|
* 사이킷런에서 좋은 성능을 내고 주목받고 있는 알고리즘들을 별도의 라이브러리로 나와 있는 것들이 다음과 같습니다.
* 부스팅계열 알고리즘(주로 정형 데이터) => XGBoost, LightGBM, CatBoost 등
* 신경망 알고리즘(주로 비정형 데이터) => TensorFlow, Keras, PyTorch 등
* 알고리즘 중에는 분류, 회귀에 따로 사용할 수 있는 것도 있고, 분류, 회귀에 모두 사용할 수 있는 것도 있습니다.
* 회귀 알고리즘 => 분류(로지스틱 회귀), 회귀(릿지, 라쏘, 엘라스틱넷) 분류에 사용하는 알고리즘과 회귀에 사용하는게 다릅니다.
* 분류 및 회귀 트리(Classification And Regression Tree, CART) => 분류와 회귀에 모두 사용할 수 있습니다.
● 결정 트리 학습법(decision tree
- 어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측 모델로서 결정 트리를 사용(예측 모델링 방법 중 하나)
- 분류트리: 트리 모델 중 목표 변수가 유한한 수의 값을 가짐
- 회귀트리: 결정 트리 중 목표 변수가 연속하는 값, 일반적으로 실수를 가짐
- 대표적인 알고리즘으로는 CART , C4.5 , CHAID 알고리즘이 있다
| 분류
- 독립변수 : 시험 공부한 시간
- 종속변수 : 시험 합격 여부(범주)
|
회귀
- 독립변수 : 시험 공부한 시간
- 종속변수 : 시험 점수(연속) |
| 질문🙋🏻♂️: graphviz 는 pip 의 graphviz 와 일반 graphviz 프로그램 두 가지를 설치해 주어야 합니다. 왜 이렇게 두 가지를 설치해 주어야 할까요?
파이썬의 특징 => 접착제 언어, 다른 도구 언어로 만들어진 도구를 파이썬으로 연결해서 사용할 수 있습니다.
그래프비즈도 마찬가지 입니다. pip 로 설치하는 graphviz 는 graphviz 기존 프로그램과 파이썬과 인터페이스 역할을 합니다.
|
| 질문🙋🏻♂️: max_depth를 3으로 지정해줬는데 max_depth 일반적으로 많이 사용하는 값이 있을까요..? 3으로 지정해도 괜찮은 건가요 ?
No Free Lunch 논문의 내용을 질문해 주셨습니다. 데이터의 크기, 변수의 개수, 데이터의 특징에 따라 max_depth 값이 달라지게 됩니다. max_depth 가 너무 적어도 언더피팅(과소적합) 너무 커도 오버피팅(과대적합)이 되게 됩니다. 여러 값을 사용해 보고 좋은 성능을 내는 값을 선택해서 사용합니다. => 이것을 찾는 과정이 하이퍼파라미터튜닝입니다
|
● 불순도 (Impurity)
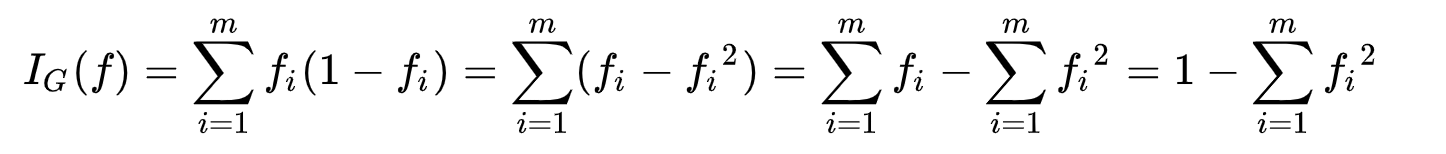
- 해당 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지를 뜻합니다.
- 다양한 개체들이 섞여 있을수록 불순도가 높아집니다.
- 모호한 정도 ( ex. 짜장과 짬뽕 중 고를 때 아무거나(반반)일 경우가 가장 모호하여 지니 불순도가 가장 높다)
지니 불순도 (분류에서 사용)
집합에 이질적인 것이 얼마나 섞였는지를 측정하는 지표 트리는 불순도가 낮아지게끔 분할 기준을 선택
만약에 49%,51%로 분할한 A와 95% 5%로 분류한 B가 있을 때 B가 순수도가 더 높다(A가 불순도가 더 높다)
지니계수가 0이 되면 완전히 나뉜 상태이기 때문에 그리는 것을 멈춤
| 질문🙋🏻♂️: 엔트로피 크기가 작을수록 집합이 순수하게 잘 분류된 것인가요 ? (0에 가까울수록) 값이 작을수록 순수도가 높으며 같은 특성을 가진 객체들로만 잘 분류했다고 볼 수 있습니다 |
| 질문🙋🏻♂️: max_depth 의 모든 리프노드가 순수해 질 때까지 분할 된다는 것은 어떤 의미일까요? 나눴을 때 엔트로피, 지니불순도가 0이 되는것은 괜찮으나 샘플의 수가 1~3개 정도로 너무 작다면 일반화하기 어려워서 오버피팅 되는 상태라고 볼 수 있습니다. |
● 머신러닝 모델의 성능을 개선하는 방법
- 데이터 분할
- 데이터 전처리, 결측치 처리
- 피처 선택, 피처 엔지니어링(스케일링, 변환, 인코딩)
- 파라미터 값을 변경하는 방법
| 질문🙋🏻♂️: 사이킷런으로 전처리를 할 때 fit은 train 에만 해줍니다. transform 은 train, test 에 둘 다 해줍니다. 왜 그럴까요? 전처리 => train 에만 fit을 하는 이유는 train 기준으로 test 데이터도 변환하기 위해 test 에 다시 fit을 하게 되면 기준이 달라지게 됩니다. * fit => train * transform => train, test |
| 질문🙋🏻♂️: max_features 는 랜덤하게 feature를 누락시키나요 ? 랜덤하게 누락시킵니다. RandomForest, Boosting 알고리즘 처럼 트리를 여러 개 만들 때는 서로 다른 피처로 트리를 만들기 때문에 중요한 역할을 합니다. |
'멋쟁이사자처럼 > Python' 카테고리의 다른 글
| 멋사 AI스쿨 TIL - (21) (0) | 2023.03.15 |
|---|---|
| 멋사 AI스쿨 TIL - (20) (0) | 2023.03.15 |
| 멋사 AI스쿨 TIL - (18) (0) | 2023.03.07 |
| 멋사 AI스쿨 TIL - (17) (0) | 2023.03.07 |
| 멋사 AI스쿨 TIL - (16) (0) | 2023.02.28 |