
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 파이썬
- GNN
- DFS
- pyhton
- BFS
- 멋쟁이사자처럼
- 멋사
- GIS
- likelion
- likelionlikelion
- 멋재이사자처럼
- TiL
- 시각화
- SQL
- seaborn
- 그리디
- 마이온
- parklab
- 인턴10
- intern10
- Plotly
- Join
- DP
- ux·ui디자인
- 프로젝트
- 알고리즘
- folium
- 멋쟁이사자처럼멋쟁이사자처럼
- Python
- 마이온컴퍼니
- Today
- Total
목록seaborn (3)
지금은마라톤중
 Seaborn Tutorial (2)_A high-level API for statistical graphics
Seaborn Tutorial (2)_A high-level API for statistical graphics
데이터를 시각화하는 가장 좋은 방법은 없다. seaborn은 일관된 데이터 세트 지향 API를 사용하여 다양한 시각적 표현 사이를 쉽게 전환할 수 있다. relplot() : 다양한 통계적 관계를 시각화하도록 설계 - relplot 함수 안에 kind 파라미터를 통해 그래프의 종류를 쉽게 바꿀 수 있다. dots = sns.load_dataset("dots") sns.relplot( data = dots, kind = "line", x = "time", y = "firing_rate", col = "align", hue = "choice", size = "coherence", style = "choice", facet_kws = dict(sharex=False), ) size와 style 파라미터는 sc..
 멋사 AI스쿨 TIL - (14)
멋사 AI스쿨 TIL - (14)
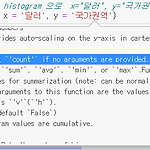
20203.02.07 🙋🏻♂️질문 : sns.heatmap(), df.style.background_gradient() => 두 가지의 차이점? heatmap은 전체를 기준으로 확인할 때, background_gradient는 axis를 조절하여 행 또는 열 기준으로도 확인df.style.background_gradient() => 성질이 다른 각 변수를 각각 비교하고자 할 때 적합합니다. 예) 변수에 체중, 키, BMI지수, 콜레스테롤수치 처럼 스케일값이 다르고 성질이 다른 값의 스케일을 비교하고자 할 때 적합합니다. 🙋🏻♂️질문 : 왜 groupby 로 할 수 있는 것은 pivot_table로도 대부분 구현이 가능할까요? pivot_table이 groupby의 하이레벨 인터페이스 입니다 자유도가 ..
 멋사 AI스쿨 TIL - (13)
멋사 AI스쿨 TIL - (13)
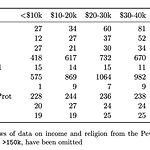
2023.02.06 ● Tidy-data => 깔끔한 데이터 🙋🏻♂️질문 : 왜 이 데이터는 깔끔한 데이터가 아닐까요? - 한 열에 하나의 변수가 있는게 아니라 다양한 열에 하나의 변수가 분포되어 있습니다 - 각 행이 개별 관측치가 아니라 집계가 되어 있는 데이터입니다. - 이전에 실습했던 서울코로나 데이터 => 각 행이 개별 관측치, 각 확진자에 대한 정보를 담고 있다. - 일별 시세 관측 데이터와 집계 데이터 중 어떤 것 일까요? => 집계데이터 ● pandas는 tidy data를 위해 melt라는 기능을 제공한다. ● melt() - 열에 있던 데이터를 행으로 녹인다. - wide-form => pandas plot()으로 막대의 색상을 다르게 지정하거나, 서브플롯을 그리거나, 시각화 하기에 좋..