
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 멋쟁이사자처럼
- kgc
- DP
- 시각화
- Rag
- Join
- ux·ui디자인
- TiL
- likelion
- SQL
- 멋재이사자처럼
- parklab
- 마이온
- 알고리즘
- intern10
- folium
- seaborn
- 인턴10
- 프로젝트
- 마이온컴퍼니
- 파이썬
- 멋사
- DFS
- paper review
- tog
- likelionlikelion
- GNN
- graphrag
- 그리디
- Python
- Today
- Total
지금은마라톤중
멋사 AI스쿨 TIL - (31) 본문
2023.04.12
PyTorch
● torch.FloatTensor()
: 입력된 텐서의 데이터 타입을 32비트 부동소수점(torch.float32)으로 변경
● 이미지, 음성, 텍스트 등 다양한 데이터를 모델 입력으로 제공하기 위해서는 데이터를 부동소수점 형태의 텐서로 변환하는 과정이 필요합니다.
-> GPU에 맞는 연산 가능한 형태로 데이터를 바꿉니다
TF => scikit-learn style API 와 유사
PyTorch => NumPy API 와 유사
● batch
=> 작게 지정하면 학습을 더 빠르게 진행할 수 있으나, 클래스가 여러개인 분류 문제에서 클래스가 불균형하게 학습하지 않도록 주의가 필요합니다.
● batch size
훈련 데이터 하나의 크기를 256이라고 해봅시다. [3, 1, 2, 5, ...] 이런 숫자들의 나열이 256의 길이로 있다고 상상하면 됩니다. 다시 말해 훈련 데이터 하나 = 벡터의 차원은 256입니다. 만약 이런 훈련 데이터의 개수가 3000개라고 한다면, 현재 전체 훈련 데이터의 크기는 3,000 × 256입니다. 행렬이니까 2D 텐서네요. 3,000개를 1개씩 꺼내서 처리하는 것도 가능하지만 컴퓨터는 훈련 데이터를 하나씩 처리하는 것보다 보통 덩어리로 처리합니다. 3,000개에서 64개씩 꺼내서 처리한다고 한다면 이 때 batch size를 64라고 합니다. 그렇다면 컴퓨터가 한 번에 처리하는 2D 텐서의 크기는 (batch size × dim) = 64 × 256입니다.
| 질문🙋🏻♂️ : 텐서플로의 Sequential 과 어떤 차이가 있을까요? 입출력의 크기를 맞춰줍니다 텐서플로에서는 출력값만을 파라미터로 전달했는데, 파이토치에서는 입출력 값을 모두 파라미터로 전달해줍니다 활성화 함수를 별도의 함수로 지정해줍니다 |
| 질문🙋🏻♂️ : sigmoid 와 softmax 는 어디에서 사용할까요? sigmoid => activation function 으로 사용했지만, 기울기 소실 문제 때문에 활성화 함수(activation function)로는 잘 사용하지 않고 이진 분류의 출력을 확률 값으로 만들어 줄 때 사용합니다. 0~1사이의 값으로 출력합니다. softmax => 분류의 output logit 값에 대한 확률 변환을 할 때 사용합니다. 클래스의 수 만큼 출력이 되며 모든 클래스를 다 더했을 때 1이 됩니다. 클래스가 10개라면 10개의 확률값을 출력하고 10개의 확률값을 다 더했을 때 1이 됩니다. |
| 질문🙋🏻♂️ : Relu 가 무엇일까요? 활성화 함수에서 기울기 소실 문제를 해결하기 위해 사용합니다 |
| 질문🙋🏻♂️ : Adam 은 무엇일까요? 옵티마이저에서 경사하강법 중에 하나입니다. learning_rate 를 지정해서 학습률을 조정할 수 있습니다. |
| 질문🙋🏻♂️ : learning_rate 는 무엇일까요?
글로벌 최소값을 찾기 위해서는 이동하는 보폭, 방향, 속도 를 고려해야 하는데 => learning_rate 는 보폭에 가깝습니다.
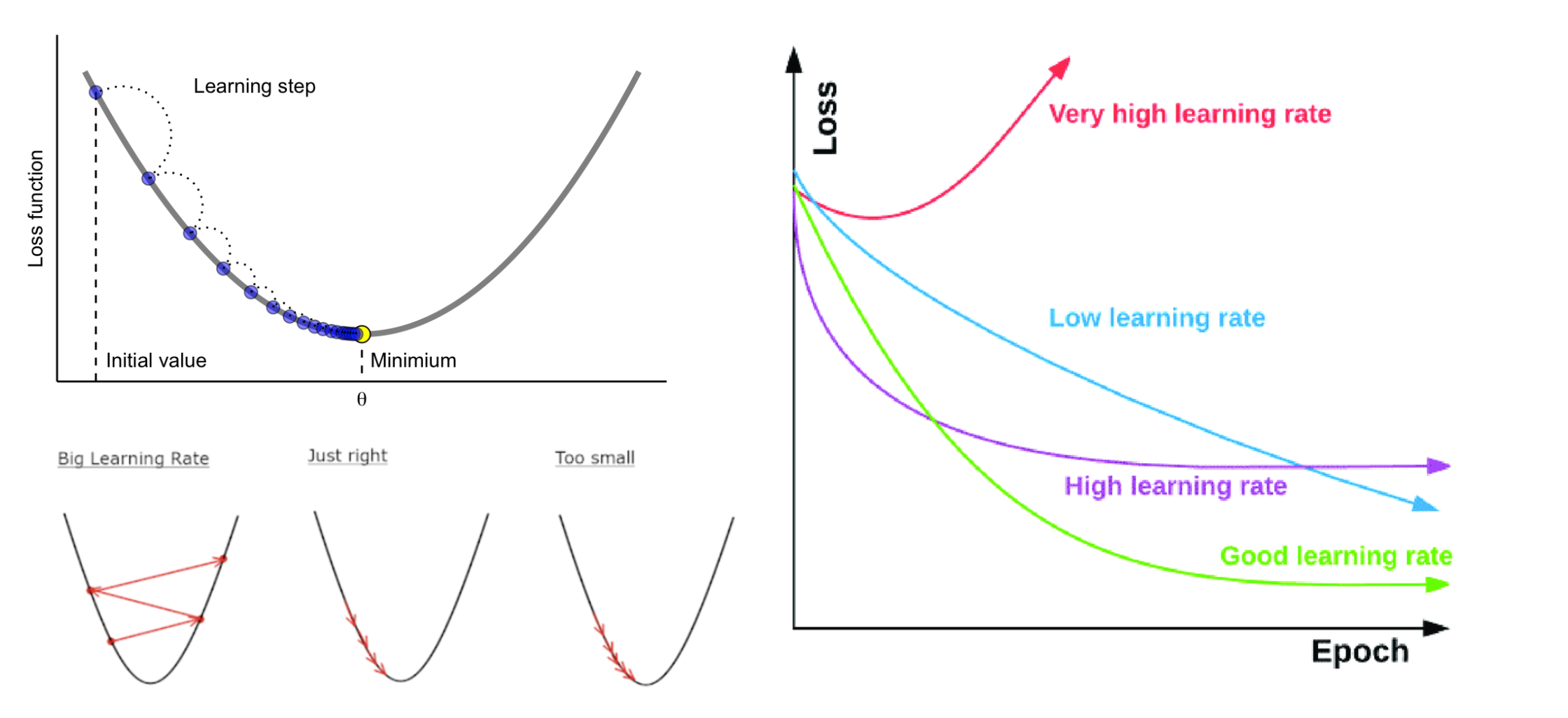 |
● Local Minima와 Global Minima
Local minima 문제는 에러를 최소화시키는 최적의 파라미터를 찾는 문제에 있어서 아래 그림처럼 파라미터 공간에 수많은 지역적인 홀(hole)들이 존재하여 이러한 local minima에 빠질 경우 전역적인 해(global minimum)를 찾기 힘들게 되는 문제를 말합니다.

● Gloabal Minima를 찾기 위한 방법 ?
- 최적화 알고리즘을 사용하여 함수의 극소점을 탐색
학습을 할 때 loss 값이 줄어들지 않고 발산을 합니다. 이때 어떤 방법을 취해 볼 수 있을까요?
우선 learning rate를 낮춰봅니다
이동하는 보폭, 방향, 속도 를 고려하거나 가중치 초기화, 데이터 정규화, Loss Function의 변경 등
● loss값의 특징
좋은 모델은 예측값과 실제 값 사이의 차이인 LOSS 를 작게 만드는 것이 목표
1) 비용 함수(Cost function) 또는 목적 함수(Objective function)로서 사용
2) 미분 가능성
3) 계산 비용이 비교적 적어야 함.
4) 모델의 목적과 일치성 ( 분류 - 엔트로피 , 회귀 - MAE, MSE ... ) .
| 질문🙋🏻♂️ : MAE보다 MSE를 일반적으로 Loss로 사용하는 이유? 1) 미분 가능성 - 경사 하강법과 같은 최적화 알고리즘을 쉽 적용 가능 2) 이상치에 덜 민감 - 실제와 예측 간 차이의 제곱을 사용하기 때문 3) 평균 제곱근 오차 RMSE 계산 가능 4) 최적화 과정에서 빠르게 수렴 - 예측 오차가 큰 경우, 제곱한 오차를 더 크게 반영한다는 특징 |
질문🙋🏻♂️ : Flatten() 을 가장 위에서 해주는 이유?
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits- 모델의 입력 데이터를 1차원 벡터 형태로 변환하여 모델의 입력 데이터 형태를 바꾸어줍닌다.
- 레이어에서 1차원 벡터를 입력받을 수 있도록 준비합니다.
● 학습, 검증 데이터 나누는 순서
1. train, test의 object type을 category type으로 변경하기! -> select_dtypes, astype('category')사용
2. train, test의 category type 피쳐에 ordinal 인코딩 해주기 train에 fit_transform, test에는 transform
3. X, y 만들기 (X=> train에서 타겟 컬럼(y)를 drop, y는 train 의 타겟 컬럼(y))
4. X, y와 test로 X_train, y_train, X_valid, y_valid, X_test, y_test 만들기
| 질문🙋🏻♂️ : validation을 사용하는 이유? 1) 현업 => 실제 비즈니스에 적용해 보기 전에는 얼마나 모델을 신뢰할 수 있을지 평가가 필요합니다. 2) 경진대회 => 예측 결과를 매번 제출해 보기 번거롭습니다. 진행 중인 경진대회는 제출횟수가 정해져 있습니다. 여러 번 제출하고 싶어도 어뷰징 이슈가 있을 수 있어서 여러 번 제출할 수 없습니다. |
질문🙋🏻♂️ : optimizer.step() 에서 .step() 이 의미하는게 무엇일까요?
# 역전파
optimizer.zero_grad()
loss.backward()
optimizer.step()러닝레이트를 의미합니다
* optimizer.zero_grad()
* optimizer 객체의 zero_grad() 메서드를 호출하여 모델의 매개변수들의 기울기를 초기화.
* 이전에 계산된 기울기 값이 남아있는 것을 방지
* loss.backward().
* 모델의 출력값 y_pred과 정답값 y_train 간의 손실(loss)을 구한 후,
* 해당 손실(loss)에 대한 모델의 가중치(weight)에 대한 기울기(gradient)를 계산
* backward() 메서드를 호출하여 수행.
* Autograd 기능을 사용하여 자동으로 기울기를 계산.
* Autograd는 모델의 입력과 출력에 대한 미분 값을 계산하여 각 매개변수의 기울기를 구하는데 사용.
* optimizer.step().
* 모델의 매개변수들의 기울기를 사용하여 가중치(weight)를 갱신.
* 선택된 최적화 알고리즘(SGD, Adam 등)에 따라 가중치 갱신.
* 모델의 가중치는 이러한 반복적인 역전파(backpropagation) 과정을 통해 조정됨
* 손실 함수를 최소화하는 방향으로 학습이 진행
* torch.no_grad()는 Autograd 엔진이 트래킹하는 것을 멈추어서 메모리 사용량을 줄이고 연산 속도를 높입니다.
* 예측값을 구할 때, 미분이 필요하지 않으므로 torch.no_grad()를 사용합니다.
CNN
● 이미지 데이터를 평면화할 때 발생하는 문제점
(공간 정보 손실)
고유 특성이 파괴된다 ! -> 지역적인 정보가 소실될 우려가 있다 !
질문🙋🏻♂️ : 마지막에 있는 softmax 는 무엇을 의미할까요?  마지막에 있는 softmax 는 무엇을 의미할까요? => 이미지 분류 문제임을 알 수 있고 마지막에 출력층을 통해 나온 logit 값을 softmax 로 확률을 구해서 반환해 주고 있다는 것을 알 수 있습니다. 확률값이 가장 높게 나오는게(np.argmax) 해당 클래스가 되게 됩니다 |
| 질문🙋🏻♂️ : 랜덤하게 여러개의 커널을 만들어서 합성곱 연산을 하면 어떤 효과가 있을까요? 랜덤값을 만들어서 합성곱 연산을 하게 되면 여러 특징을 학습할 수 있습니다. => 랜덤하게 동그라미, 선, 뾰족함 등 다양한 패턴을 생성할 수 있습니다. |
● 커널(kernel) 이란?
: 입력 이미지의 특징을 추출하는 데 중요한 역할
- 각 커널은 입력 이미지에서 다른 특징을 추출합니다. 이렇게 추출된 특징 맵(feature map)은 다음 레이어로 전달되어 최종적으로 분류(classification)나 회귀(regression) 등의 작업을 수행합니다.
ex) 3x3 크기의 커널을 사용한다고 했을 때, 입력 이미지의 3x3 영역과 커널의 원소를 각각 곱한 후 모두 더하여 출력 값을 계산할 수 있습니다.
합성곱 연산 => 특징을 추출
풀링 연산 => 이미지 추상화(압축, 사이즈 줄이는 효과, 오버피팅도 방지)
● 컨볼루션 신경망(Convolutional Neural Network) 레이어 구성
- 합성곱(Convolution)과 풀링(Pooling) 과정이 반복적으로 수행된다 !
-> 입력 이미지에서 특징을 추출하고, 이미지의 크기를 줄이거나 강하게 활성화된 특징을 보존하는 작업을 반복하여 최종적으로 분류나 회귀 등의 작업을 수행할 수 있도록 학습한다 !
● 용어정리
filters : 정수, 출력 공간의 차원(즉, 컨볼루션의 출력 필터 수), 컨볼루션 필터의 수 == 특징맵 수
strides : 높이와 너비에 따른 컨볼루션의 보폭을 지정하는 정수 또는 정수 2개로 구성된 튜플/리스트
kernel_size : 컨볼루션 커널의 (행, 열) => 필터 사이즈
padding : 경계 처리 방법
- ‘valid’ : 유효한 영역만 출력이 됩니다. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작습니다.
- ‘same’ : 출력 이미지 사이즈가 입력 이미지 사이즈와 동일합니다.
- padding = same이고 strides=1 이면 출력은 입력과 동일한 크기를 갖는다
input_shape : 모델에서 첫 레이어일 때만 정의하면 됨 (batchSize, height, width, channels) activation : 활성화 함수 설정합니다.
- ‘linear’ : 디폴트 값, 입력뉴런과 가중치로 계산된 결과값이 그대로 출력
- ‘relu’ : rectifier 함수, 은닉층에 주로 사용
- ‘sigmoid’ : 시그모이드 함수, 이진 분류 문제에서 출력층에 주로 사용
- ‘softmax’ : 소프트맥스 함수, 다중 클래스 분류 문제에서 출력층에 주로 사용
| 질문🙋🏻♂️ : padding='same'과 padding=1 이 똑같은 의미인가요? 같은 의미입니다. |
| 질문🙋🏻♂️ : padding='same'과 padding=1 이렇게 해주면 어떤 효과가 있을까요? => 1픽셀씩 가장자리 부분을 0으로 채워주게 됩니다 => 입력과 출력의 사이즈를 같게 해줄 수 있으며, 모서리 부분을 더 잘 학습할 수 있습니다. |
| 질문🙋🏻♂️ : model.add(layers.MaxPooling2D(pool_size=(2, 2))) 왜 FC 층 바로 전에 model.add(layers.MaxPooling2D(pool_size=(2, 2))) 을 해주어야 할까요? 과적합을 방지하기 위해서 입니다. Convolution과 달리, 이미지를 압축하여 특정 구간에서 가장 큰 값을 추출합니다. 이렇게 하면 이미지의 크기가 줄어들어서 연산량을 줄일 수 있습니다. 또한, 작은 변화나 이미지 내의 노이즈를 제거하여 이미지 특징을 강화하는 효과도 있습니다 |
● Map 구분
Feature Map - 합성곱 레이어 통과
Activation Map - 활성화함수 레이어 통과
| 질문🙋🏻♂️ : 스트라이드는 보통 1을 사용하는데 이 값을 크게 지정하면 어떤 효과가 있을까요? 스트라이드 값을 크게 설정하면 더 큰 거리를 이동하면서 입력 데이터를 처리하므로 출력 데이터(output)의 크기가 줄어들게 됩니다. 이러한 결과로 인해 모델의 계산 비용이 줄어들게 됩니다. 그러나 스트라이드 값을 크게 설정하면 입력 데이터의 중요한 정보가 누락될 수 있으므로 모델의 성능이 저하될 수 있습니다. 또한 스트라이드 값을 크게 설정하면 과적합(overfitting) 문제가 발생할 가능성이 높아집니다. |
● 데이터 증강: 기준 데이터로부터 이미지를 랜덤하게 생성하여 데이터의 수를 늘림
● Drop-out
: 서로 연결된 연결망(layer)에서 0부터 1 사이의 확률로 뉴런을 제거하는 기법
● Data Augmentation 기법
: 데이터의 양을 늘리기 위해 원본에 각종 변환을 적용하여 개수를 증강시키는 기법
- Cropping, Mirroring(대칭), Random, Roatation, Shearing, Local wraping 등등
● utils.image_dataset_from_directory()
directory : 데이터 셋 디렉토리 경로
validation_split : 검증 데이터셋의 비율
batch_size : 데이터를 한 번에 처리하는 크기를 지정
image_size : 이미지의 크기를 지정
subset : 데이터셋에서 일부분을 선택
- None (디폴트) : 전체 데이터셋을 사용합니다.
-" training" : 학습 데이터셋만 사용합니다.
- "validation" : 검증 데이터셋만 사용합니다
● PIL 이미지 작업을 위한 표준 절차를 제공하고 있으며, 다음과 같은 것이있다.
픽셀 단위의 조작
마스킹 및 투명도 제어
흐림, 윤곽 보정 다듬어 윤곽 검출 등의 이미지 필터
선명하게, 밝기 보정, 명암 보정, 색 보정 등의 화상 조정
이미지에 텍스트 추가
기타 여러 가지
PIL => 이미지 처리
OpenCV => 이미지 + 영상
● OpenCV(Open Source Computer Vision)
실시간 컴퓨터 비전을 목적으로 한 프로그래밍 라이브러리이다. 원래는 인텔이 개발하였다. 실시간 이미지 프로세싱에 중점을 둔 라이브러리이다. 인텔 CPU에서 사용되는 경우 속도의 향상을 볼 수 있는 IPP(Intel Performance Primitives)를 지원한다. 이 라이브러리는 윈도, 리눅스 등에서 사용 가능한 크로스 플랫폼이며 오픈소스 BSD 허가서 하에서 무료로 사용할 수 있다. OpenCV는 TensorFlow , Torch / PyTorch 및 Caffe의 딥러닝 프레임워크를 지원한다.
'멋쟁이사자처럼 > Python' 카테고리의 다른 글
| 멋사 AI스쿨 TIL - (33) (0) | 2023.04.18 |
|---|---|
| 멋사 AI스쿨 TIL - (32) (0) | 2023.04.18 |
| 멋사 AI스쿨 TIL - (30) (0) | 2023.04.18 |
| 멋사 AI스쿨 TIL - (29) (0) | 2023.04.18 |
| 멋사 AI스쿨 TIL - (28) (0) | 2023.04.18 |

