멋사 AI스쿨_SQL_TIL (6)
2023.02.03
ROLLUP
- 집계된 데이터에서 그룹별 소계, 총계를 구하기 위해서 사용
- ex) rollup( gender)
### SQL 연습문제
-- thelook_ecommerce 데이터 세트, 회원(users) 테이블에서 연령대 별 성별의 소계 및 합계를 조회하시오
SELECT
TRUNC(age, -1) || '대' AS age_group,
gender,
COUNT(id) AS user_count
FROM
`thelook_ecommerce.users`
GROUP BY
ROLLUP(age_group,
gender)
ORDER BY
age_group
| 🙋🏻♂️질문 : SELECT문에 선언된 순서대로 필드를 1, 2처럼 숫자로 표현하는 경우가 있던데 현업에서도 많이 사용하는 방법인가요?? - 가독성의 차이인 것 같다. - 1,2로 표현할 수는 있는데 이게 더 가독성이 좋다고 생각되면 사용하면 된다. |
WINDOW 함수
- input -> 처리 -> output
- 현재 행과 관련이 있는 테이블 행들에 대해 계산을 수행
- 분석함수라고도 부름
- 행 그룹에 대해 하나의 결과를 반환하는 집계 함수와는 다름
- OVER 절을 포함, 이 절은 평가 중인 행을 중심으로 행의 기간을 정의
- 이동 평균, 항목의 순위, 누적 합계를 계산하고, 기타 분석을 수행할 수 있음
-> 전체 결과를 한번에 반환하는 것이 아닌 매번 선택된 행의 범위를 다르게 하여 값을 반환
● window 함수 종류
- 탐색 함수 : LEAD, LAG, FIRST_VALUE, LAST_VALUE
- 번호 지정 함수 : RANK, DENSE_RANK, PERCENT_RANK, CUME_DIST, NTILE
- 집계 분석 함수 : 집계 함수들, AVG, COUNT, SUM, MAX, MIN
● 문법
- 함수 이름(컬럼, OFFSET) OVER (PARTITION BY 파티션_컬럼 ORDER BY 정렬_컬럼)
- OFFSET : 값을 가져올 행의 위치. 기본 값은 1이고 생략 가능
- 함수 이름(컬럼) OVER (PARTITION BY 파티션_컬럼 ORDER BY 정렬_컬럼)
- 필요에 따라 PARTITION BY는 생략 가능
● window 함수의 분류
- 그룹 내 순위 관련 함수(RANKING FAMILY)
- RANK
- 현재 행의 순위를 부여
- 동일 값인 경우 동일 순위가 부여되고, 다음 순위는 동일값의 수만큼 건너뛰어 부여
- DENSE_RANK
- 현재 행의 순위를 부여
- 동일 값인 경우 동일 순위가 부여되고, 다음 순위는 건너뛰지 않고 순차 번호로 부여
- 공동순위가 존재x
- ROW_NUMBER
- 1부터 순차적으로 하나씩 증가하는 번호를 생성
- RANK
 |
# Rows 범위 지정
select
id,
email,
created_at,
first_value(id) over( order by id ) as first_id,
last_value(id) over(
order by id
rows between UNBOUNDED PRECEDING and CURRENT ROW
) as last_id,
last_Value(id) over(
order by id
rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING
) as last_id_unbounded
from `thelook_ecommerce.users`
where id between 1 and 10
order by id
그룹 내 집계 관련 함수(WINDOW AGGREGATE FAMILY)
- SUM : 윈도우 내에서 지정된 value의 합을 계산
- MAX : 윈도우 내에서 지정한 value의 최대값을 반환
- MIN : 윈도우 내에서 지정한 value의 최소값을 반환
- AVG : 윈도우 내에서 지정한 value의 평균값을 계산
- COUNT : 윈도우 내에서 지정한 value에 대해 존재하는 행을 카운트
* sum은 over() 안에 아무것도 안 넣어도 된다.
over()에 아무것도 안 넣으면 모든 행을 기준으로 결과를 변환한다.
모든 것이 그런건 아니고 sum은 그렇다.
select
value,
sum(value) over(
order by value
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) as running_total
from `weniv.value_list`
order by id
# 상품정보와 상품의 브랜드 평균가격
select
id, brand, name, cost, retail_price,
avg(retail_price) over(partition by brand) as avg_retail_price
from `thelook_ecommerce.products`
limit 100;
select id,
name,
category,
retail_price,
COUNT(id) OVER() as count_product,
COUNT(id) OVER(PARTITION BY category) as count_category_product
from `thelook_ecommerce.products`
order by id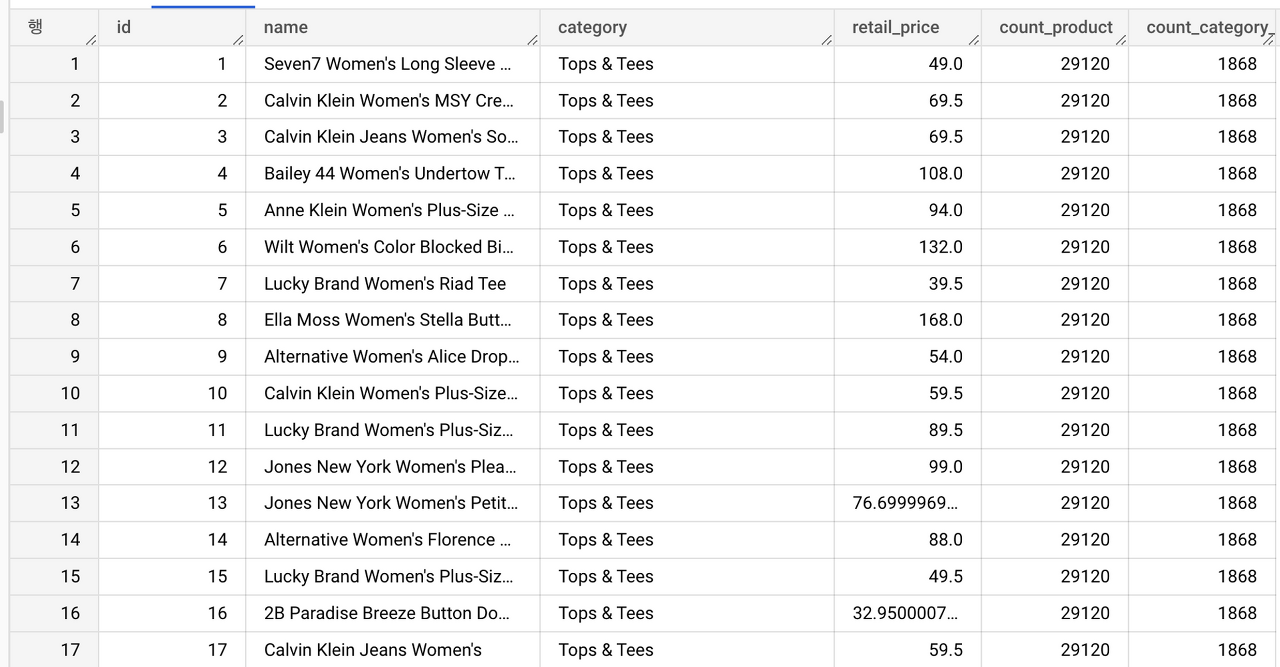
그룹 내 행 순서 관련 함수
● LAG
- 이전 행의 필드를 읽고 반환
- 기본값은 1이며 순서 지정 가능
● LEAD(바로뒤행)
- 다음 행의 필드를 읽고 반환
- 기본값은 1이며 순서 지정 가능
select
id,
first_name,
last_name,
lead(id, 2) over(
order by id
) as id_next
from `thelook_ecommerce.users`
where id between 1 and 20
order by id
| 🙋🏻♂️질문 : LEAD를 사용해서 다음 행 말고, 2번 뒤의 행을 가져와 볼수도 있나요 ? - lead(id, 2) 처럼 옵션을 지정할 수 있다. |
● FIRST_VALUE
- 그룹 내의 첫값
● LAST_VALUE
- 그룹 내의 마지막 값
- LAST_VALUE는 지금까지 읽은 행의 집합을 의미하기 때문에 항상 자기 자신
- 전체 그룹에 대한 마지막 값을 구하려면 ROWS 옵션을 주어야 함
● NTH_VALUE
- 그룹 내의 N번째 행의 값을 반환
- 이 행이 없으면 NULL을 반환
#NTH_VALUE
select
id,
email,
created_at,
NTH_VALUE(id, 5) OVER ( ORDER BY id ) as second_signup_user_id,
NTH_VALUE(id, 5) OVER (
ORDER BY id
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) as second_signup_user_id,
NTH_VALUE(created_at, 5) OVER ( ORDER BY id ) as second_signup_user_created_at
from `thelook_ecommerce.users`
where id between 1 and 20
order by id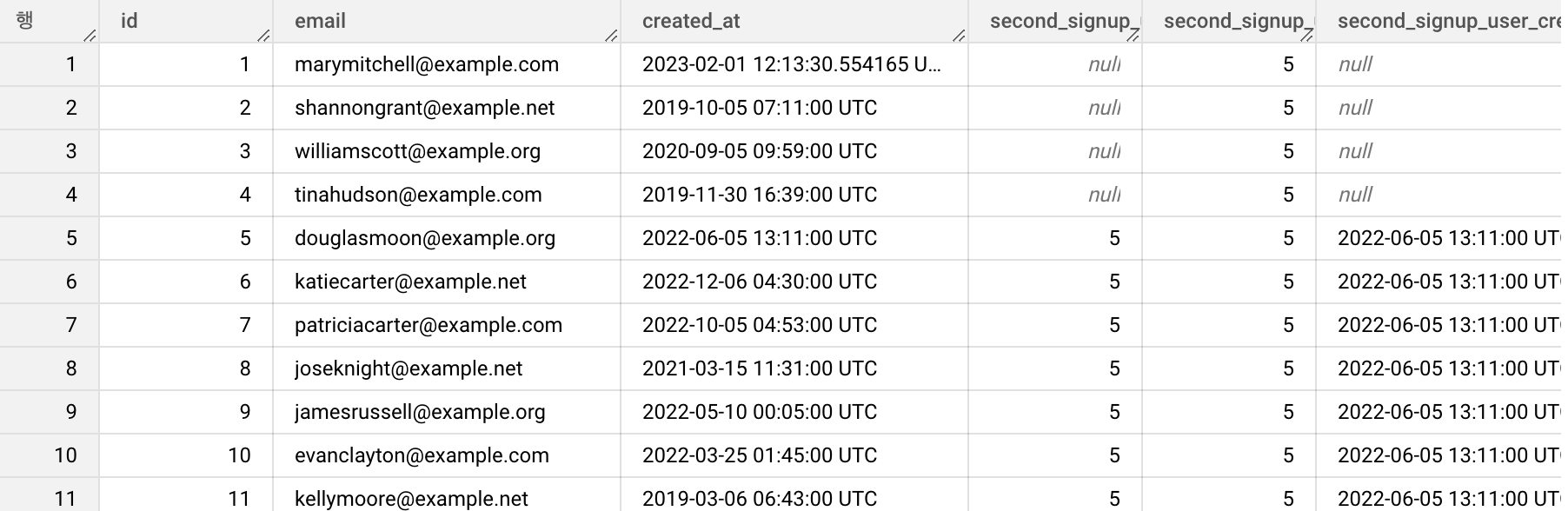
그룹 내 비율 관련 함수
● CUME_DIST(cumulative distribution, 누적분포)
- 0보다 크고 1보다 작거나 같은 값이 나옴.
- n보다 값이 작은 행의 갯수 / 현재 window 또는 파티션의 row 개수
select value,
cume_dist() over(
order by value
) cumulative_distribution
from `weniv.value_list`;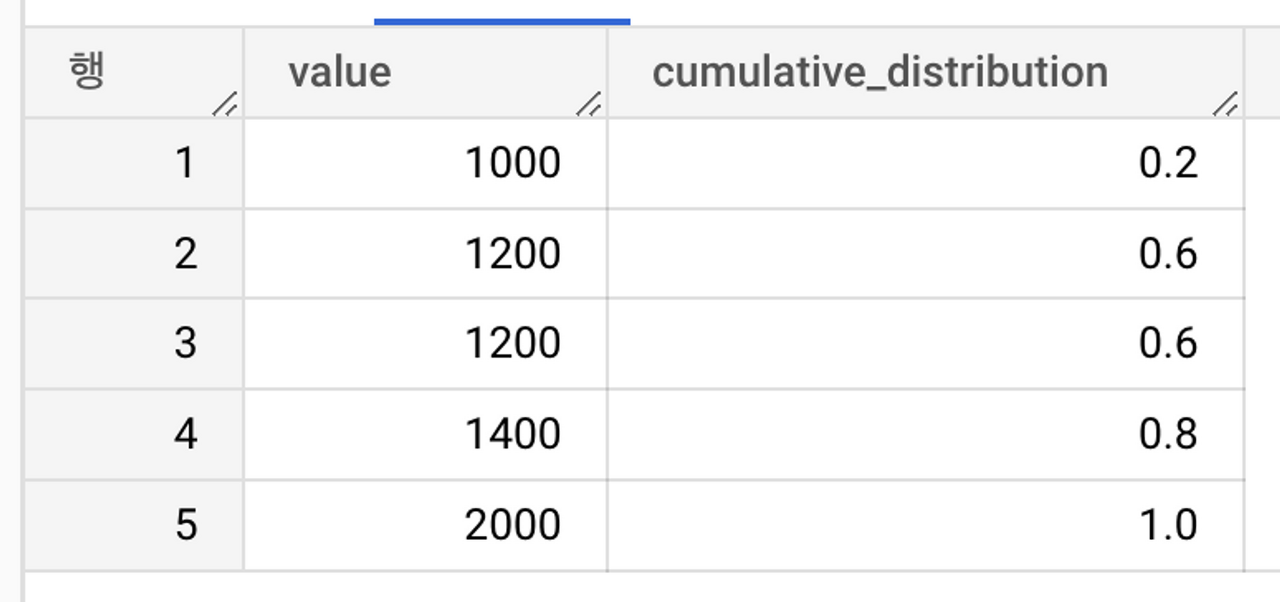
● PERCENT_RANK
- 현재 행의 상대적 순위를 반환
- 계산에 따라 0과 1사이의 범위에서 행의 백분율 순위를 계산
- ex. 상위 몇 퍼센트
● NTILE(n개의 그룹으로 나눔)
- 집합을 n개의 영역으로 구분하고 소속 영역을 반환
- 인수 n은 나눌 영역의 개수를 지정
- ex) 8개를 3개로 나눌 때 3 / 3 / 2
select
id,
first_name,
last_name,
country,
age,
ntile(4) over (order by age) as tile_number
from `thelook_ecommerce.users`
where id between 1 and 20
order by age
데이터 수정 (INSERT / DELETE / UPDATE)
● INSERT
테이블에 새 레코드를 삽입할 때 사용합니다.
INSERT INTO weniv_product (삽입할 열 이름1, 삽입할 열 이름2, ... )
VALUES (값1, 값2, ... );INSERT INTO weniv_product VALUES (12, 'ballpen', 500);
● DELETE
- 기존 레코드를 삭제합니다.
- 조건을 주어 원하는 행만 삭제합니다.
DELETE FROM 테이블명
WHERE 조건;DELETE FROM weniv_product
WHERE id > 5;
● UPDATE
조건에 맞는 기존 레코드를 수정할 수 있습니다. where로 여러개를 select하여 바꿀 수 있습니다.
- where 문이 있으면 where문에 대해서만 업데이트한다.
- where 문이 없으면 전체에 대해 업데이트한다.
UPDATE 테이블명
SET 컬럼명1 = 값1, 컬럼명2 = 값2, ...
WHERE 조건;UPDATE weniv_product
SET cost = 50000